Spring&Spring Boot
Spring&Spring Boot
1.什么是 Spring 框架?
Spring 是一款开源的轻量级 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性。
我们一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。
比如说 Spring 自带 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)、可以很方便地对数据库进行访问、可以很方便地集成第三方组件(电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
2.列举一些重要的 Spring 模块?
下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
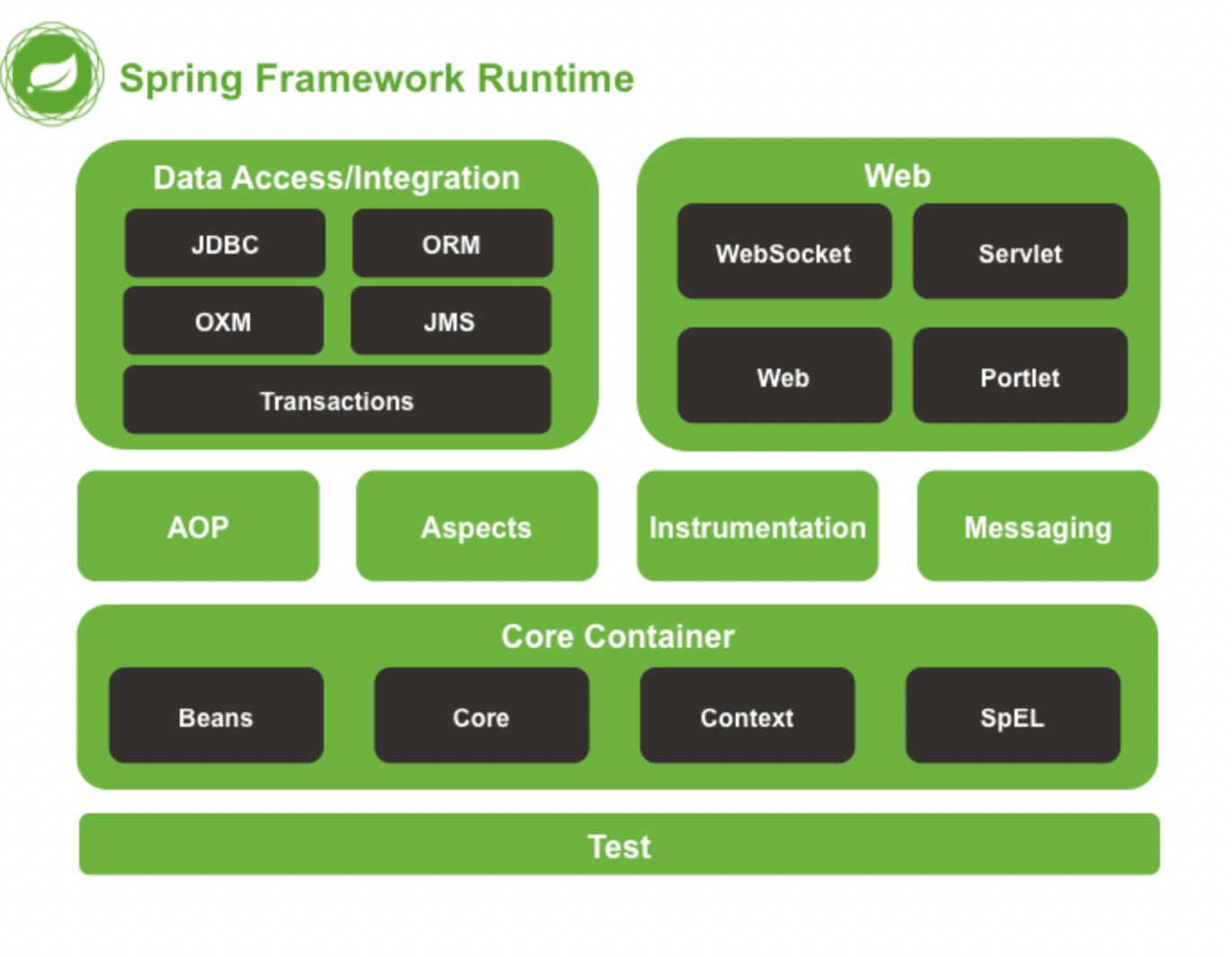
Spring Core
核心模块, Spring 其他所有的功能基本都需要依赖于该模块,主要提供 IoC 依赖注入功能的支持。
Spring Aspects
该模块为与 AspectJ 的集成提供支持。
Spring AOP
提供了面向切面的编程实现。
Spring Data Access/Integration :
Spring Data Access/Integration 由 5 个模块组成:
- spring-jdbc : 提供了对数据库访问的抽象 JDBC。不同的数据库都有自己独立的 API 用于操作数据库,而 Java 程序只需要和 JDBC API 交互,这样就屏蔽了数据库的影响。
- spring-tx : 提供对事务的支持。
- spring-orm : 提供对 Hibernate 等 ORM 框架的支持。
- spring-oxm : 提供对 Castor 等 OXM 框架的支持。
- spring-jms : Java 消息服务。
Spring Web
Spring Web 由 4 个模块组成:
- spring-web :对 Web 功能的实现提供一些最基础的支持。
- spring-webmvc : 提供对 Spring MVC 的实现。
- spring-websocket : 提供了对 WebSocket 的支持,WebSocket 可以让客户端和服务端进行双向通信。
- spring-webflux :提供对 WebFlux 的支持。WebFlux 是 Spring Framework 5.0 中引入的新的响应式框架。与 Spring MVC 不同,它不需要 Servlet API,是完全异步.
Spring Test
Spring 团队提倡测试驱动开发(TDD)。有了控制反转 (IoC)的帮助,单元测试和集成测试变得更简单。
Spring 的测试模块对 JUnit(单元测试框架)、TestNG(类似 JUnit)、Mockito(主要用来 Mock 对象)、PowerMock(解决 Mockito 的问题比如无法模拟 final, static, private 方法)等等常用的测试框架支持的都比较好。
Spring Context
Spring 上下文是一个配置文件,向 Spring 框架提供上下文信息。Spring 上下文包括企业服务,例如 JNDI、EJB、电子邮件、国际化、事件机制、校验和调度功能。
3.Spring,Spring MVC,Spring Boot 之间什么关系?
Spring 包含了多个功能模块,其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。于是,Spring Boot 诞生了!
Spring 旨在简化 J2EE 企业应用程序开发。Spring Boot 旨在简化 Spring 开发(减少配置文件,开箱即用!)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用!
4.谈谈自己对于 Spring IoC 的了解?
IoC(Inverse of Control:控制反转) 是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spring 特有,在其他语言中也有应用。
为什么叫控制反转?
- 控制 :指的是对象创建(实例化、管理)的权力
- 反转 :控制权交给外部环境(Spring 框架、IoC 容器)
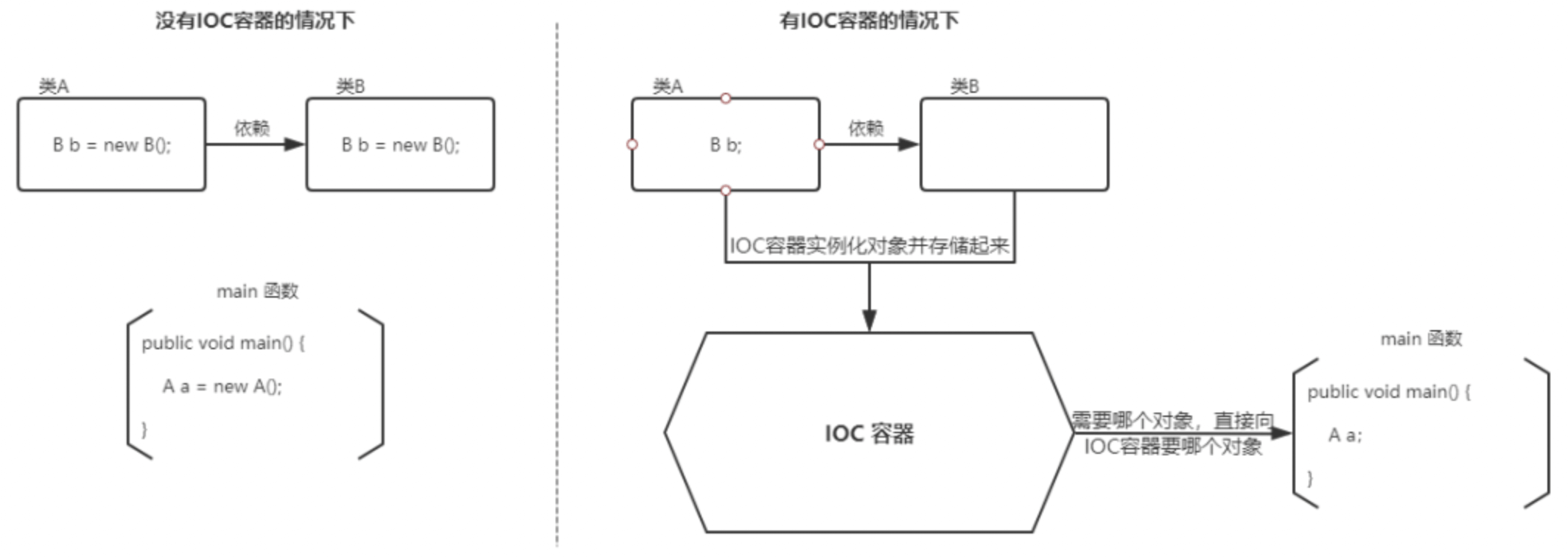
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
在实际项目中一个 Service 类可能依赖了很多其他的类,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
5.谈谈自己对于 AOP 的了解?
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
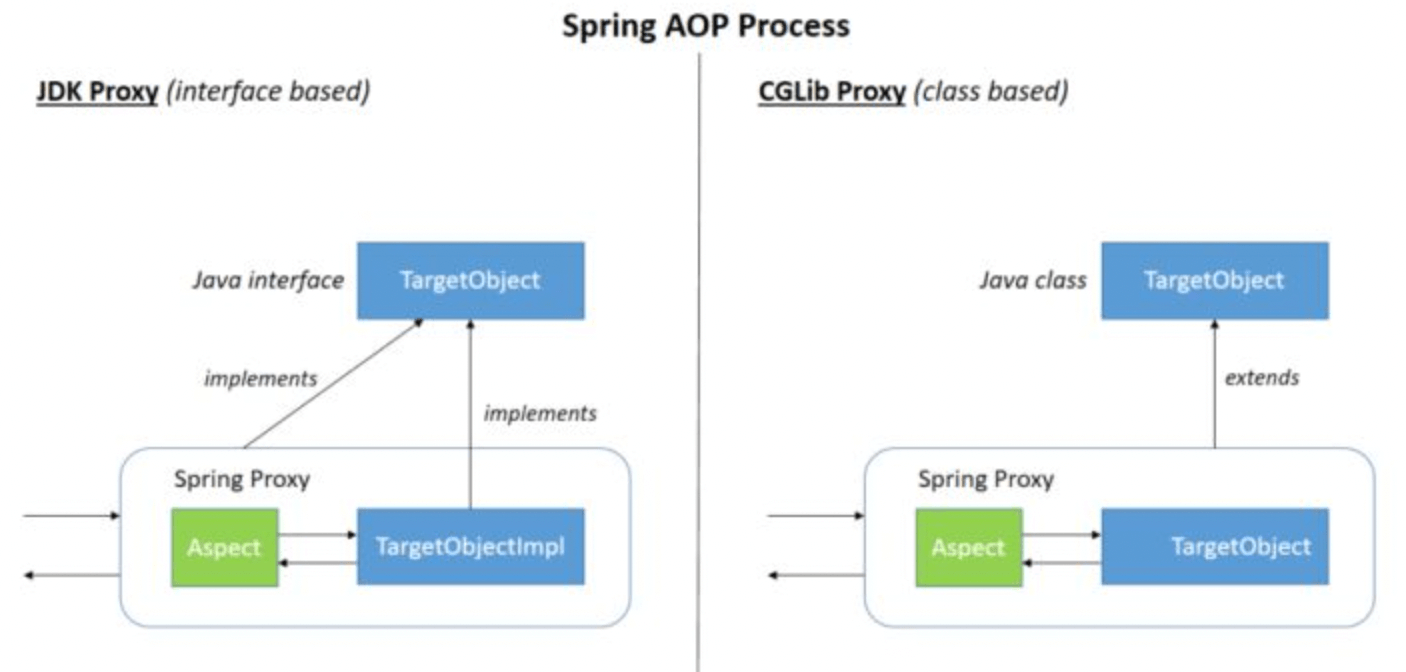
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
6.Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单。
Spring AOP 仅支持方法级别的 PointCut;AspectJ提供了完全的 AOP 支持, 它还支持属性级 别的 PointCut。
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
7.什么是 Spring Bean?
简单来说,Bean 代指的就是那些被 IoC 容器所管理的对象。
8.将一个类声明为 Bean 的注解有哪些?
@Component:通用的注解,可标注任意类为Spring组件。如果一个 Bean 不知道属于哪个层,可以使用@Component注解标注。@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
9.@Component 和 @Bean 的区别是什么?
@Component注解作用于类,而@Bean注解作用于方法。@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用@ComponentScan注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。@Bean注解比@Component注解的自定义性更强,而且很多地方我们只能通过@Bean注解来注册 bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
10.注入 Bean 的注解有哪些?
Spring 内置的 @Autowired 以及 JDK 内置的 @Resource 和 @Inject 都可以用于注入 Bean。
| Annotaion | Package | Source |
|---|---|---|
@Autowired | org.springframework.bean.factory | Spring 2.5+ |
@Resource | javax.annotation | Java JSR-250 |
@Inject | javax.inject | Java JSR-330 |
@Autowired 和@Resource使用的比较多一些。
Autowired 属于 Spring 内置的注解,默认的注入方式为byType(根据类型进行匹配),也就是说会优先根据接口类型去匹配并注入 Bean (接口的实现类)。
这会有什么问题呢? 当一个接口存在多个实现类的话,byType这种方式就无法正确注入对象了,因为这个时候 Spring 会同时找到多个满足条件的选择,默认情况下它自己不知道选择哪一个。
这种情况下,注入方式会变为 byName(根据名称进行匹配),这个名称通常就是类名(首字母小写)。 建议通过 @Qualifier 注解来显示指定名称而不是依赖变量的名称。
@Resource属于 JDK 提供的注解,默认注入方式为 byName。如果无法通过名称匹配到对应的 Bean 的话,注入方式会变为byType。
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)
如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。
11.Bean 的作用域有哪些?
Spring 中 Bean 的作用域通常有下面几种:
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的,对单例设计模式的应用。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
- global-session : 全局 session 作用域,仅仅在基于 portlet 的 web 应用中才有意义,Spring5 已经没有了。Portlet 是能够生成语义代码(例如:HTML)片段的小型 Java Web 插件。它们基于 portlet 容器,可以像 servlet 一样处理 HTTP 请求。但是,与 servlet 不同,每个 portlet 都有不同的会话。
如何配置 bean 的作用域呢?
注解方式:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
12.单例 Bean 的线程安全问题了解吗?
单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
不过,大部分 Bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
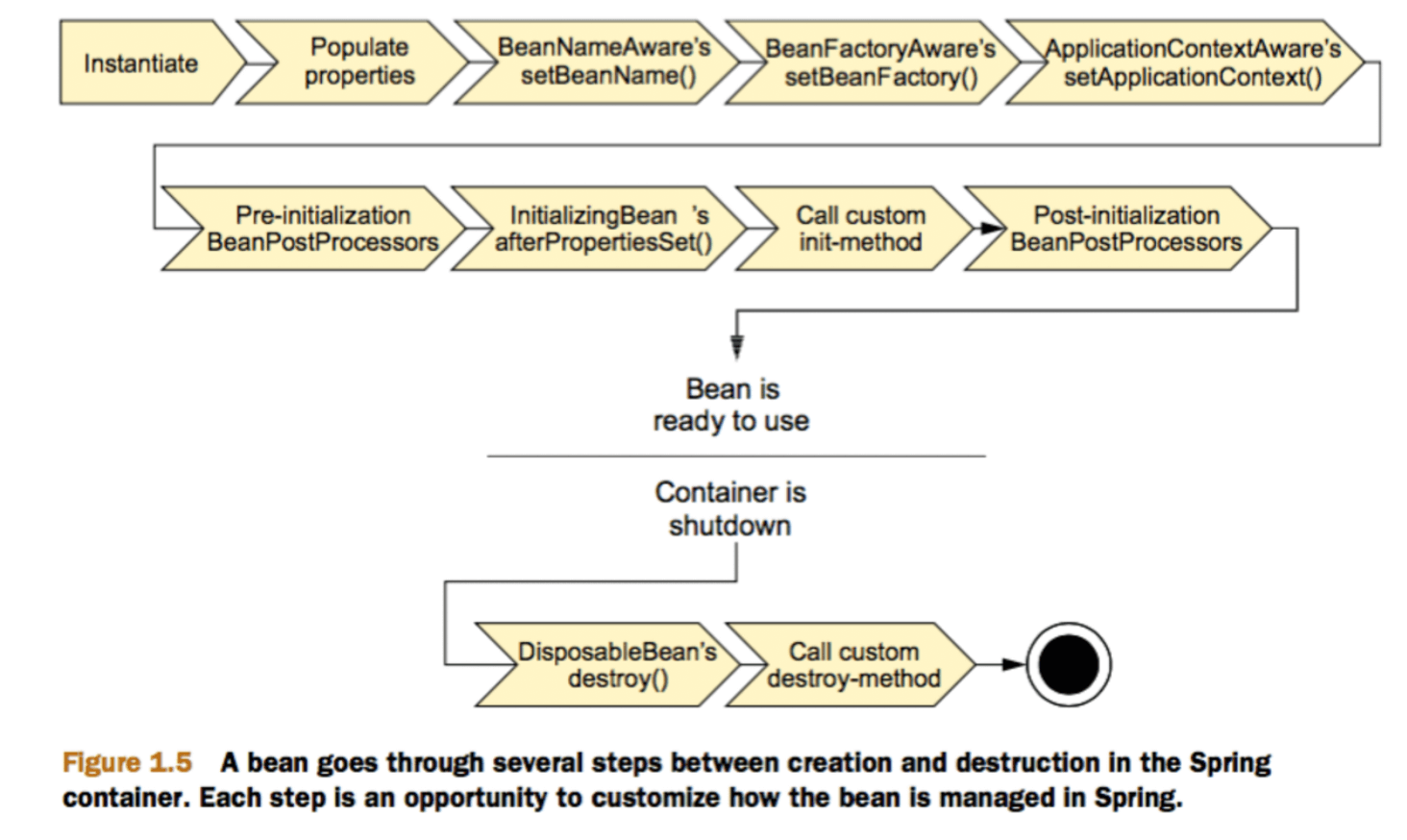
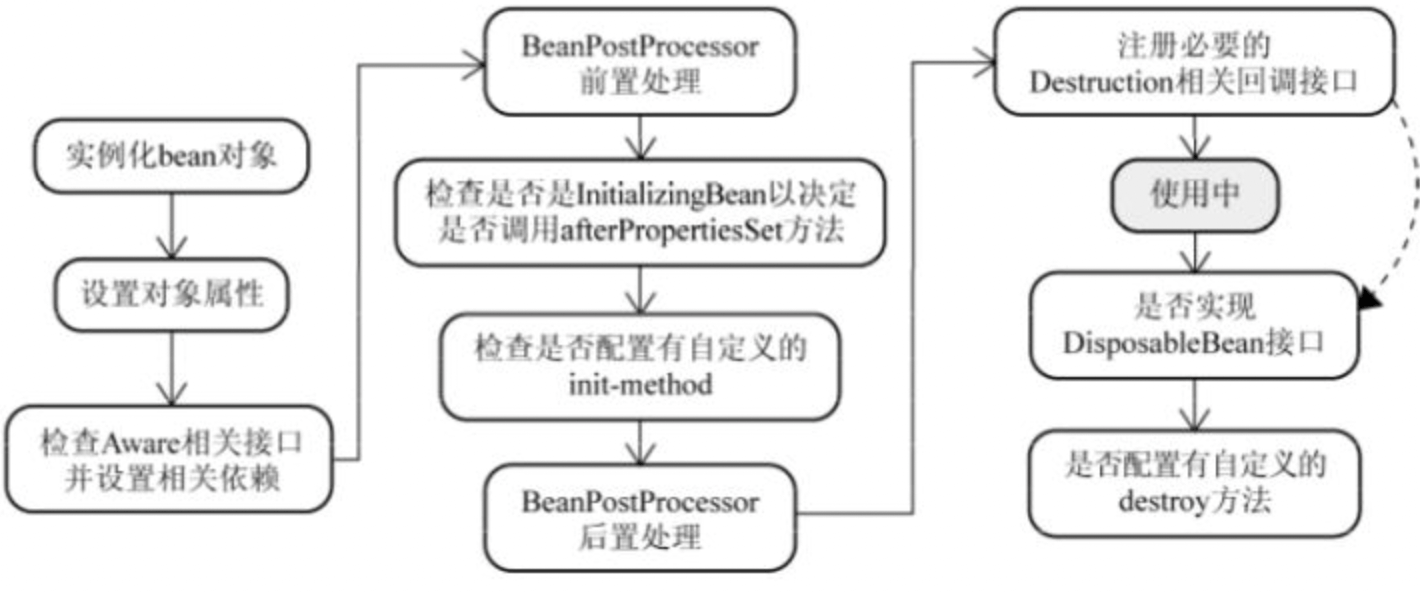
13.Bean 的生命周期了解么?
- Bean 容器找到配置文件中 Spring Bean 的定义。
- Bean 容器利用 Java Reflection API 创建一个 Bean 的实例。
- 如果涉及到一些属性值 利用
set()方法设置一些属性值。 - 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 如果 Bean 实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法。 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法。 - 当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 - 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
14.说说自己对于 Spring MVC 了解?
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
15.SpringMVC 工作原理了解吗?
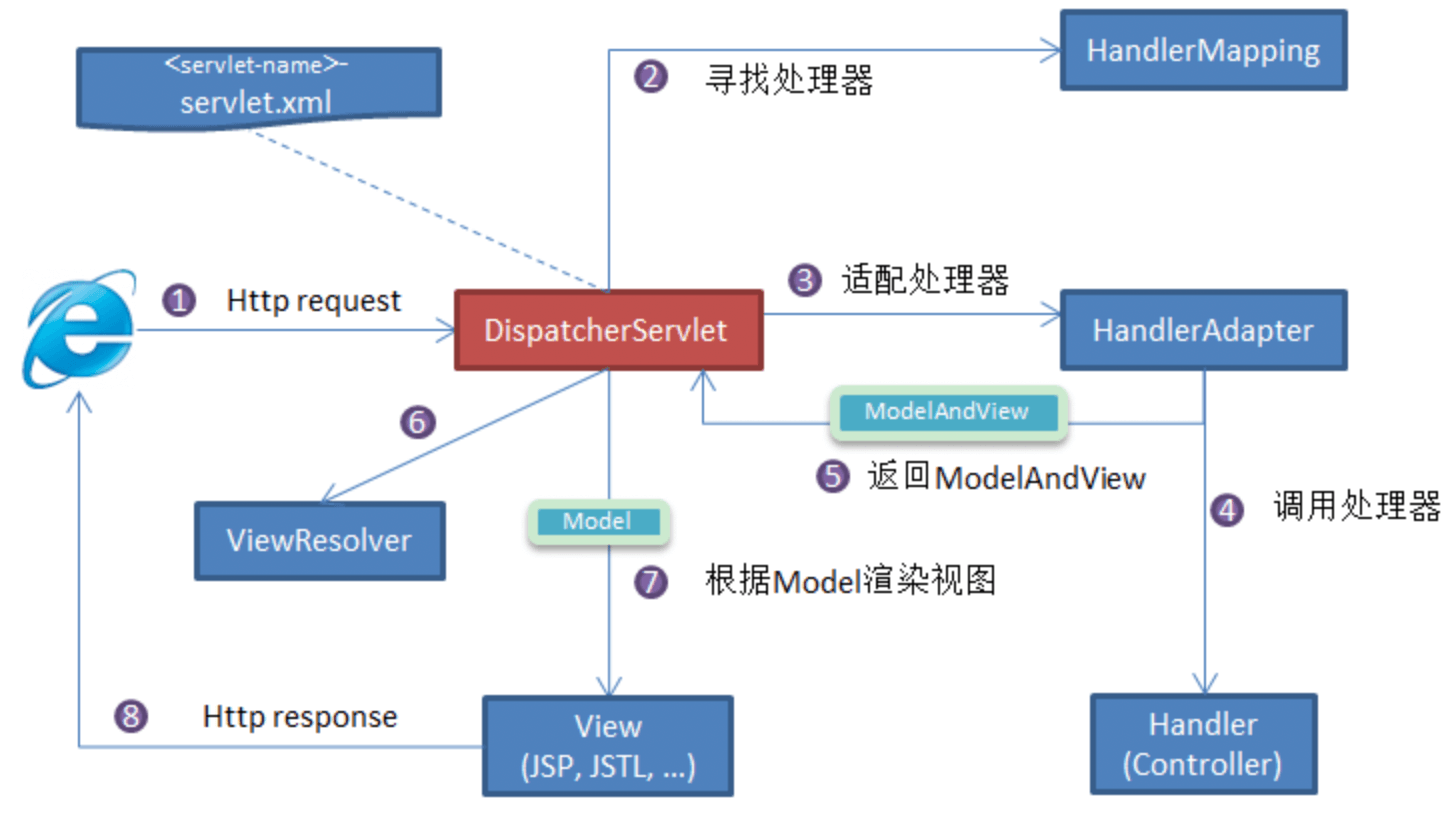
流程说明(重要):
- 客户端(浏览器)发送请求,直接请求到
DispatcherServlet。 DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。- 解析到对应的
Handler(也就是我们平常说的Controller控制器)后,开始由HandlerAdapter适配器处理。 HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。- 处理器处理完业务后,会返回一个
ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。 ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)。
16.Spring 框架中用到了哪些设计模式?
- 工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
17.Spring 管理事务的方式有几种?
- 编程式事务 : 在代码中硬编码(不推荐使用) : 通过
TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。 - 声明式事务 : 在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)
18.Spring 事务中哪几种事务传播行为?
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
正确的事务传播行为可能的值如下:
1.TransactionDefinition.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,我们平时经常使用的@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
2.TransactionDefinition.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
3.TransactionDefinition.PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
4.TransactionDefinition.PROPAGATION_MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
这个使用的很少。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
19.Spring 事务中的隔离级别有哪几种?
TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,MySQL 默认采用的REPEATABLE_READ隔离级别 Oracle 默认采用的READ_COMMITTED隔离级别。TransactionDefinition.ISOLATION_READ_UNCOMMITTED:最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
20.@Transactional(rollbackFor = Exception.class)注解了解吗?
Exception 分为运行时异常 RuntimeException 和非运行时异常。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
在 @Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚。
21.springboot的优缺点?

22.简单介绍一下@SpringbootApplication注解?

23.springboot自动装配原理?
24.@Transactional 的使用注意事项总结?
@Transactional注解只有作用到 public 方法上事务才生效,不推荐在接口上使用;因为底层cglib是基于⽗⼦类来实现 的,⼦类是不能重载⽗类的private⽅法的,所以⽆法很好的利⽤代理,也会导致@Transactianal失效- 避免同一个类中调用
@Transactional注解的方法,这样会导致事务失效;只有是被代理对象调⽤时, 那么这个注解才会⽣效,所以如果是被代理对象来调⽤这个⽅法,那么@Transactional是不会失效的。 - 正确的设置
@Transactional的rollbackFor和propagation属性,否则事务可能会回滚失败; - 被
@Transactional注解的方法所在的类必须被 Spring 管理,否则不生效; - 底层使用的数据库必须支持事务机制,否则不生效;
25.Spring 框架中用到了哪些设计模式?
- 工厂设计模式 : Spring使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
26.IOC注入哪几种方式?
基于 field 注入(属性注入)
基于 setter 注入
基于 constructor 注入(构造器注入)
- 基于 field 注入 所谓基于 field 注入,就是在bean的变量上使用注解进行依赖注入。本质上是通过反射的方式直接注入到field。这是我平常开发中看的最多也是最熟悉的一种方式,同时,也正是 Spring 团队所不推荐的方式。比如:
@Autowired private Svc svc;- 基于 setter 方法注入 通过对应变量的setXXX()方法以及在方法上面使用注解,来完成依赖注入。比如:
private Helper helper; @Autowired public void setHelper(Helper helper) { this.helper = helper; }注:在 Spring 4.3 及以后的版本中,setter 上面的 @Autowired 注解是可以不写的。
- 基于 constructor 注入 将各个必需的依赖全部放在带有注解构造方法的参数中,并在构造方法中完成对应变量的初始化,这种方式,就是基于构造方法的注入。比如:
private final Svc svc; @Autowired public HelpService(@Qualifier("svcB") Svc svc) { this.svc = svc; }在 Spring 4.3 及以后的版本中,如果这个类只有一个构造方法,那么这个构造方法上面也可以不写 @Autowired 注解。
- 强制依赖就用构造器方式
- 可选、可变的依赖就用setter 注入当然你可以在同一个类中使用这两种方法。构造器注入更适合强制性的注入旨在不变性,Setter注入更适合可变性的注入。
基于 field 注入虽然简单,但是却会引发很多的问题。
容易违背了单一职责原则
你的类和依赖容器强耦合,不能在容器外使用
不能使用属性注入的方式构建不可变对象(final 修饰的变量)
27.什么是AOP(面向切面编程)?
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术。
28.切面有几种类型的通知?分别是?
前置通知(Before): 目标方法被调用之前调用通知功能。
后置通知(After): 目标方法完成之后调用通。
返回通知(After-returning): 目标方法成功执行之后调用通知。
异常通知(After-throwing): 目标方法抛出异常后调用通知。
环绕通知(Around): 在被通知的方法调用之前和调用之后执行自定义的行为。
29.什么是连接点 (Join point)?
连接点是在应用执行过程中能够插入切面的一个点。这个点可以是调用方法时、抛出异常时、甚至修改 一个字段时。
30.什么是切点(Pointcut)?
切点的定义会匹配通知所要织入的一个或多个连接点。
我们通常使用明确的类和方法名称,或是利用正 则表达式定义所匹配的类和方法名称来指定这些切点。有些AOP框架允许我们创建动态的切点,可以根 据运行时的决策(比如方法的参数值)来决定是否应用通知。
31.什么是切面(Aspect)?
切面是通知和切点的结合。通知和切点共同定义了切面的全部内容。
32.织入(Weaving)?
织入是把切面应用到目标对象并创建新的代理对象的过程。切面在指定的连接点被织入到目标对象中。
33.在目标对象的生命周期里有多个点可以进行织入?
编译期:切面在目标类编译时被织入。AspectJ的织入编译器就是以这种方式织入切面的。
类加载期:切面在目标类加载到JVM时被织入。它可以在目标类被引入应用之前增强该目标类的字 节码。AspectJ 5的加载时织入(load-time weaving,LTW)就支持以这种方式织入切面。
运行期:切面在应用运行的某个时刻被织入。一般情况下,在织入切面时,AOP容器会为目标对象 动态地创建一个代理对象。Spring AOP就是以这种方式织入切面的。
34.AOP动态代理策略?
如果目标对象实现了接口,默认采用JDK 动态代理。可以强制转为CgLib实现AOP。 如果没有实现接口,采用CgLib进行动态代理。
35.SpringMVC的几个组件?
DispatcherServlet : 前端控制器,也叫中央控制器。相关组件都是它来调度。
HandlerMapping : 处理器映射器,根据URL路径映射到不同的Handler。
HandlerAdapter : 处理器适配器,按照HandlerAdapter的规则去执行Handler。
Handler : 处理器,由我们自己根据业务开发。
ViewResolver : 视图解析器,把逻辑视图解析成具体的视图。
View : 一个接口,它的实现支持不同的视图类型(freeMaker,JSP等)
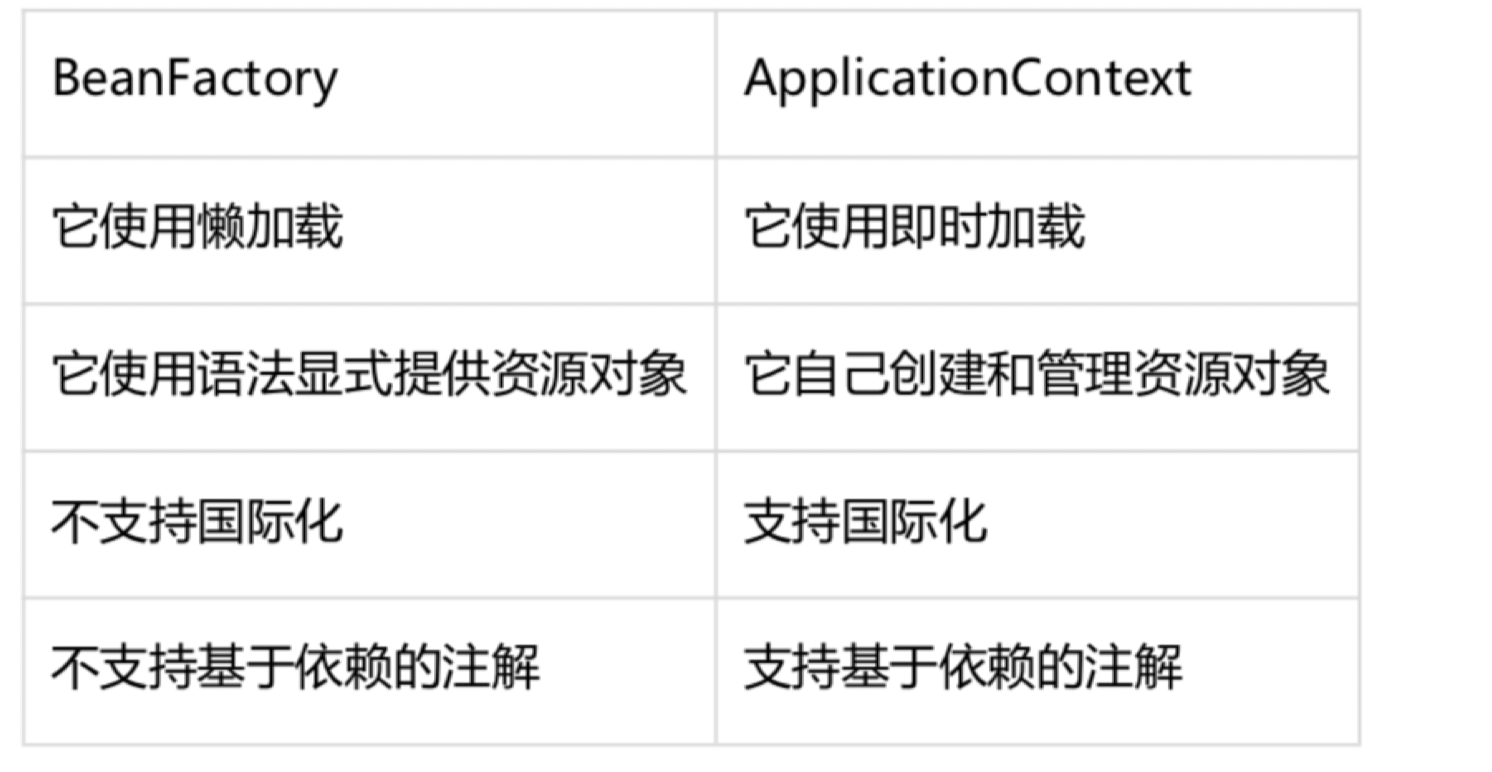
36.BeanFactory 和 ApplicationContext区别?
37.@Qualifier注解?
当创建多个相同类型的 bean 时,并且想要用一个属性只为它们其中的一个进行装配,在这种情况下, 你可以使用 @Qualifier 注释和 @Autowired 注释通过指定哪一个真正的 bean 将会被装配来消除混乱。
38.application.properties和application.yml文件可放位置?优先级?
如果是2.4.0之前版本,优先级properties>yaml , 但是如果是2.4.0的版本,优先级yaml>properties

先去项目根目录找config文件夹下找配置文件件
再去根目录下找配置文件
去resources下找cofnig文件夹下找配置文件
去resources下找配置文件

SpringBoot会加载全部主配置文件;互补配置;
备注: 这里说的配置文件,都还是项目里面。最终都会被打进jar包里面的,需要注意。
1、如果同一个目录下,有application.yml也有application.properties,默认先读取 application.properties。
2、如果同一个配置属性,在多个配置文件都配置了,默认使用第1个读取到的,后面读取的不覆盖前面读取 到的。
3、创建SpringBoot项目时,一般的配置文件放置在“项目的resources目录下”
如果我们的配置文件名字不叫application.properties或者application.yml,可以通过以下参数来指定 配置文件的名字,myproject是配置文件名
$ java -jar myproject.jar --spring.config.name=myproject
我们同时也可以指定其他位置的配置文件来生效 指定配置文件和默认加载的这些配置文件共同起作用形成互补配置。
java -jar run-0.0.1-SNAPSHOT.jar -spring.config.location=D:/application.propertie
39.bootstrap.yml 和application.yml?
bootstrap.yml 优先于application.yml
40.在Spring AOP 中,关注点和横切关注的区别是什么?
关注点是应用中一个模块的行为,一个关注点可能会被定义成一个我们想实现的一个功能。
横切关注点是一个关注点,此关注点是整个应用都会使用的功能,并影响整个应用,比如日志,安全和数据传输,几乎应用的每个模块都需要的功能。因此这些都属于横切关注点。
那什么是连接点呢?连接点代表一个应用程序的某个位置,在这个位置我们可以插入一个AOP切 面,它实际上是个应用程序执行Spring AOP的位置。
切入点是什么?切入点是一个或一组连接点,通知将在这些位置执行。可以通过表达式或匹配的方式指明切入点。
41.Spring 是怎么解决循环依赖的?

整个流程大致如下:
首先 A 完成初始化第一步并将自己提前曝光出来(通过 ObjectFactory 将自己提前曝光),在初始化的时候,发现自己依赖对象 B,此时就会去尝试 get(B),这个时候发现 B 还没有被创建出来;
然后 B 就走创建流程,在 B 初始化的时候,同样发现自己依赖 C,C 也没有被创建出来;
这个时候 C 又开始初始化进程,但是在初始化的过程中发现自己依赖 A,于是尝试 get(A)。这 个时候由于 A 已经添加至缓存中(一般都是添加至三级缓存 singletonFactories),通过 ObjectFactory 提前曝光,所以可以通过 ObjectFactory#getObject() 方法来拿到 A 对象。C 拿 到 A 对象后顺利完成初始化,然后将自己添加到一级缓存中;
回到 B,B 也可以拿到 C 对象,完成初始化,A 可以顺利拿到 B 完成初始化。到这里整个链路 就已经完成了初始化过程了。
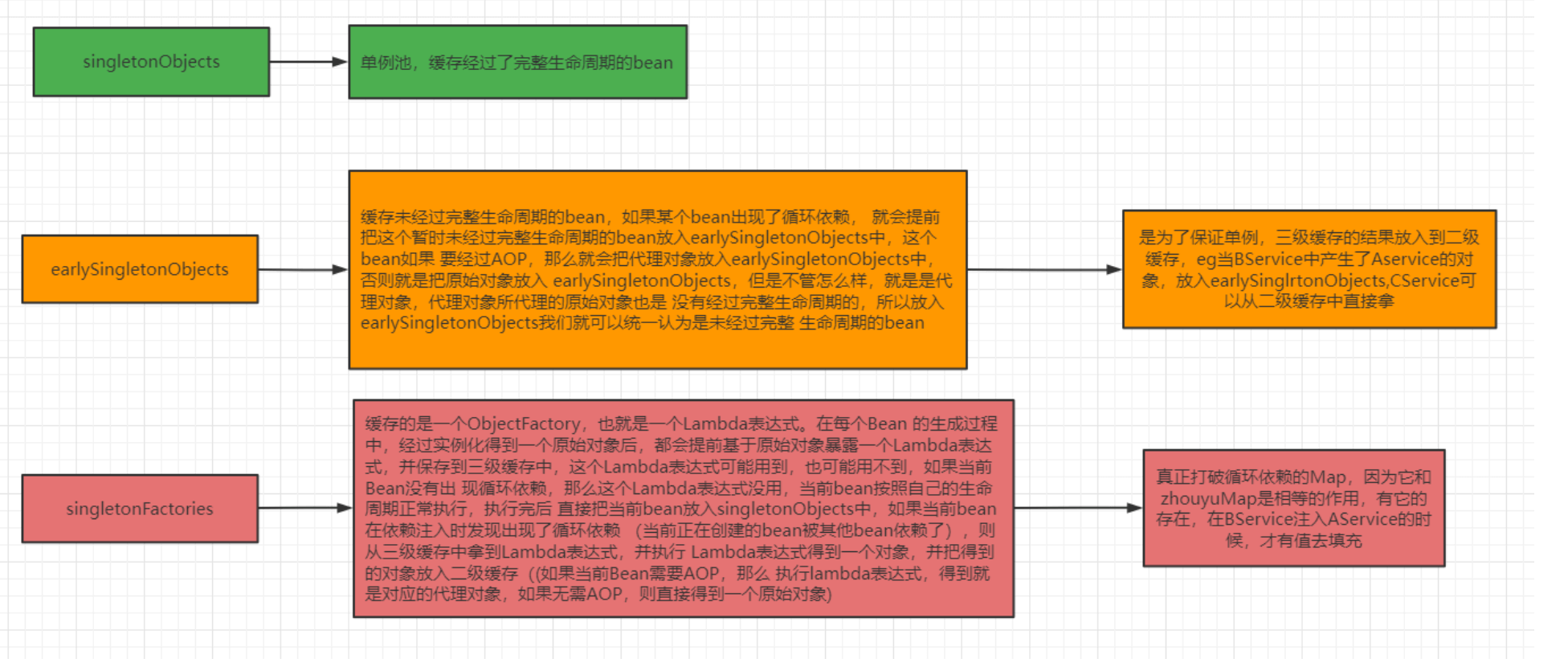
一级缓存:正式对象。
二级缓存:半成品对象。
三级缓存:工厂。
三级缓存主要处理的是AOP的代理对象,存储的是一个ObjectFactory。
三级缓存考虑的是代理对象,而二级缓存考虑的是性能-从三级缓存的工厂里创建出对象,再扔到二级缓存(这样就不用每次都要从工厂里拿)。
42.事务三要素是什么?
数据源:表示具体的事务性资源,是事务的真正处理者,如MySQL等。
事务管理器:像一个大管家,从整体上管理事务的处理过程,如打开、提交、回滚等。
事务应用和属性配置:像一个标识符,表明哪些方法要参与事务,如何参与事务,以及一些相关属 性如隔离级别、超时时间等。
43.事务注解的本质是什么?
@Transactional 这个注解仅仅是一些(和事务相关的)元数据,在运行时被事务基础设施读取消费,并使用这些元数据来配置bean的事务行为。 大致来说具有两方面功能,一是表明该方法要参与事务,二是配置相关属性来定制事务的参与方式和运行行为
声明式事务主要是得益于Spring AOP。使用一个事务拦截器,在方法调用的前后/周围进行事务性 增强(advice),来驱动事务完成。
@Transactional注解既可以标注在类上,也可以标注在方法上。当在类上时,默认应用到类里的所 有方法。如果此时方法上也标注了,则方法上的优先级高。 另外注意方法一定要是public的。
44.如何在Spring Boot启动的时候运行一些特定的代码?
如果你想在Spring Boot启动的时候运行一些特定的代码,你可以实现接口ApplicationRunner或 者CommandLineRunner,这两个接口实现方式一样,它们都只提供了一个run方法。
CommandLineRunner:启动获取命令行参数
45.如何实现一个IOC容器?
IOC(Inversion of Control),意思是控制反转,不是什么技术,而是一种设计思想,IOC意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
在传统的程序设计中,我们直接在对象内部通过new进行对象创建,是程序主动去创建依赖对象,而IOC是有专门的容器来进行对象的创建,即IOC容器来控制对象的创建。
在传统的应用程序中,我们是在对象中主动控制去直接获取依赖对象,这个是正转,反转是由容器来帮忙创建及注入依赖对象,在这个过程过程中,由容器帮我们查找级注入依赖对象,对象只是被动的接受依赖对象。
1、先准备一个基本的容器对象,包含一些map结构的集合,用来方便后续过程中存储具体的对象
2、进行配置文件的读取工作或者注解的解析工作,将需要创建的bean对象都封装成BeanDefinition对象存储在容器中
3、容器将封装好的BeanDefinition对象通过反射的方式进行实例化,完成对象的实例化工作
4、进行对象的初始化操作,也就是给类中的对应属性值就行设置,也就是进行依赖注入,完成整个对象的创建,变成一个完整的bean对象,存储在容器的某个map结构中
5、通过容器对象来获取对象,进行对象的获取和逻辑处理工作
6、提供销毁操作,当对象不用或者容器关闭的时候,将无用的对象进行销毁
46.什么的是bean的自动装配
自动装配是使用spring满足bean依赖的一种方法
spring会在应用上下文中为某个bean寻找其依赖的bean
no – 缺省情况下,自动配置是通过“ref”属性手动设定,在项目中最常用 byName – 根据属性名称自动装配。如果一个bean的名称和其他bean属性的名称是一样的,将会自装配它。 byType – 按数据类型自动装配,如果bean的数据类型是用其它bean属性的数据类型,兼容并自动装配它。 constructor – 在构造函数参数的byType方式。 autodetect – 如果找到默认的构造函数,使用“自动装配用构造”; 否则,使用“按类型自动装配”。
47.springboot自动配置原理是什么?
下面详细讲解自动装配的过程。
1、在springboot的启动过程中,有一个步骤是创建上下文:
public ConfigurableApplicationContext run(String... args) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
Banner printedBanner = printBanner(environment);
context = createApplicationContext();
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
//此处完成自动装配的过程
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
refreshContext(context);
afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
listeners.started(context);
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
2、在prepareContext方法中查找load方法,一层一层向内点击,找到最终的load方法
//prepareContext方法
private void prepareContext(ConfigurableApplicationContext context, ConfigurableEnvironment environment,
SpringApplicationRunListeners listeners, ApplicationArguments applicationArguments, Banner printedBanner) {
context.setEnvironment(environment);
postProcessApplicationContext(context);
applyInitializers(context);
listeners.contextPrepared(context);
if (this.logStartupInfo) {
logStartupInfo(context.getParent() == null);
logStartupProfileInfo(context);
}
// Add boot specific singleton beans
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
beanFactory.registerSingleton("springApplicationArguments", applicationArguments);
if (printedBanner != null) {
beanFactory.registerSingleton("springBootBanner", printedBanner);
}
if (beanFactory instanceof DefaultListableBeanFactory) {
((DefaultListableBeanFactory) beanFactory)
.setAllowBeanDefinitionOverriding(this.allowBeanDefinitionOverriding);
}
if (this.lazyInitialization) {
context.addBeanFactoryPostProcessor(new LazyInitializationBeanFactoryPostProcessor());
}
// Load the sources
Set<Object> sources = getAllSources();
Assert.notEmpty(sources, "Sources must not be empty");
//load方法完成该功能
load(context, sources.toArray(new Object[0]));
listeners.contextLoaded(context);
}
/**
* Load beans into the application context.
* @param context the context to load beans into
* @param sources the sources to load
* 加载bean对象到context中
*/
protected void load(ApplicationContext context, Object[] sources) {
if (logger.isDebugEnabled()) {
logger.debug("Loading source " + StringUtils.arrayToCommaDelimitedString(sources));
}
//获取bean对象定义的加载器
BeanDefinitionLoader loader = createBeanDefinitionLoader(getBeanDefinitionRegistry(context), sources);
if (this.beanNameGenerator != null) {
loader.setBeanNameGenerator(this.beanNameGenerator);
}
if (this.resourceLoader != null) {
loader.setResourceLoader(this.resourceLoader);
}
if (this.environment != null) {
loader.setEnvironment(this.environment);
}
loader.load();
}
/**
* Load the sources into the reader.
* @return the number of loaded beans
*/
int load() {
int count = 0;
for (Object source : this.sources) {
count += load(source);
}
return count;
}
3、实际执行load的是BeanDefinitionLoader中的load方法,如下:
//实际记载bean的方法
private int load(Object source) {
Assert.notNull(source, "Source must not be null");
//如果是class类型,启用注解类型
if (source instanceof Class<?>) {
return load((Class<?>) source);
}
//如果是resource类型,启动xml解析
if (source instanceof Resource) {
return load((Resource) source);
}
//如果是package类型,启用扫描包,例如@ComponentScan
if (source instanceof Package) {
return load((Package) source);
}
//如果是字符串类型,直接加载
if (source instanceof CharSequence) {
return load((CharSequence) source);
}
throw new IllegalArgumentException("Invalid source type " + source.getClass());
}
4、下面方法将用来判断是否资源的类型,是使用groovy加载还是使用注解的方式
private int load(Class<?> source) {
//判断使用groovy脚本
if (isGroovyPresent() && GroovyBeanDefinitionSource.class.isAssignableFrom(source)) {
// Any GroovyLoaders added in beans{} DSL can contribute beans here
GroovyBeanDefinitionSource loader = BeanUtils.instantiateClass(source, GroovyBeanDefinitionSource.class);
load(loader);
}
//使用注解加载
if (isComponent(source)) {
this.annotatedReader.register(source);
return 1;
}
return 0;
}
5、下面方法判断启动类中是否包含@Component注解,但是会神奇的发现我们的启动类中并没有该注解,继续更进发现MergedAnnotations类传入了一个参数SearchStrategy.TYPE_HIERARCHY,会查找继承关系中是否包含这个注解,@SpringBootApplication-->@SpringBootConfiguration-->@Configuration-->@Component,当找到@Component注解之后,会把该对象注册到AnnotatedBeanDefinitionReader对象中
private boolean isComponent(Class<?> type) {
// This has to be a bit of a guess. The only way to be sure that this type is
// eligible is to make a bean definition out of it and try to instantiate it.
if (MergedAnnotations.from(type, SearchStrategy.TYPE_HIERARCHY).isPresent(Component.class)) {
return true;
}
// Nested anonymous classes are not eligible for registration, nor are groovy
// closures
return !type.getName().matches(".*\\$_.*closure.*") && !type.isAnonymousClass()
&& type.getConstructors() != null && type.getConstructors().length != 0;
}
/**
* Register a bean from the given bean class, deriving its metadata from
* class-declared annotations.
* 从给定的bean class中注册一个bean对象,从注解中找到相关的元数据
*/
private <T> void doRegisterBean(Class<T> beanClass, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, @Nullable Supplier<T> supplier,
@Nullable BeanDefinitionCustomizer[] customizers) {
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(beanClass);
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(supplier);
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
if (customizers != null) {
for (BeanDefinitionCustomizer customizer : customizers) {
customizer.customize(abd);
}
}
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
/**
* Register the given bean definition with the given bean factory.
* 注册主类,如果有别名可以设置别名
*/
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
//@SpringBootApplication
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {}
//@SpringBootConfiguration
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {}
//@Configuration
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Configuration {}
当看完上述代码之后,只是完成了启动对象的注入,自动装配还没有开始,下面开始进入到自动装配。
6、自动装配入口,从刷新容器开始
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
// 此处是自动装配的入口
invokeBeanFactoryPostProcessors(beanFactory);
}
7、在invokeBeanFactoryPostProcessors方法中完成bean的实例化和执行
/**
* Instantiate and invoke all registered BeanFactoryPostProcessor beans,
* respecting explicit order if given.
* <p>Must be called before singleton instantiation.
*/
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
//开始执行beanFactoryPostProcessor对应实现类,需要知道的是beanFactoryPostProcessor是spring的扩展接口,在刷新容器之前,该接口可以用来修改bean元数据信息
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
8、查看invokeBeanFactoryPostProcessors的具体执行方法
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set<String> processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
//开始遍历三个内部类,如果属于BeanDefinitionRegistryPostProcessor子类,加入到bean注册的集合,否则加入到regularPostProcessors
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
//通过BeanDefinitionRegistryPostProcessor获取到对应的处理类“org.springframework.context.annotation.internalConfigurationAnnotationProcessor”,但是需要注意的是这个类在springboot中搜索不到,这个类的完全限定名在AnnotationConfigEmbeddedWebApplicationContext中,在进行初始化的时候会装配几个类,在创建AnnotatedBeanDefinitionReader对象的时候会将该类注册到bean对象中,此处可以看到internalConfigurationAnnotationProcessor为bean名称,容器中真正的类是ConfigurationClassPostProcessor
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
//首先执行类型为PriorityOrdered的BeanDefinitionRegistryPostProcessor
//PriorityOrdered类型表明为优先执行
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
//获取对应的bean
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
//用来存储已经执行过的BeanDefinitionRegistryPostProcessor
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
//开始执行装配逻辑
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
//其次执行类型为Ordered的BeanDefinitionRegistryPostProcessor
//Ordered表明按顺序执行
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
//循环中执行类型不为PriorityOrdered,Ordered类型的BeanDefinitionRegistryPostProcessor
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
//执行父类方法,优先执行注册处理类
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
//执行有规则处理类
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}
9、开始执行自动配置逻辑(启动类指定的配置,非默认配置),可以通过debug的方式一层层向里进行查找,会发现最终会在ConfigurationClassParser类中,此类是所有配置类的解析类,所有的解析逻辑在parser.parse(candidates)中
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
//是否是注解类
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
//执行配置类
this.deferredImportSelectorHandler.process();
}
-------------------
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
processConfigurationClass(new ConfigurationClass(metadata, beanName));
}
-------------------
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass);
do {
//循环处理bean,如果有父类,则处理父类,直至结束
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
10、继续跟进doProcessConfigurationClass方法,此方式是支持注解配置的核心逻辑
/**
* Apply processing and build a complete {@link ConfigurationClass} by reading the
* annotations, members and methods from the source class. This method can be called
* multiple times as relevant sources are discovered.
* @param configClass the configuration class being build
* @param sourceClass a source class
* @return the superclass, or {@code null} if none found or previously processed
*/
@Nullable
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
//处理内部类逻辑,由于传来的参数是启动类,并不包含内部类,所以跳过
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass);
}
// Process any @PropertySource annotations
//针对属性配置的解析
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
// 这里是根据启动类@ComponentScan注解来扫描项目中的bean
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
//遍历项目中的bean,如果是注解定义的bean,则进一步解析
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
//递归解析,所有的bean,如果有注解,会进一步解析注解中包含的bean
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
//递归解析,获取导入的配置类,很多情况下,导入的配置类中会同样包含导入类注解
processImports(configClass, sourceClass, getImports(sourceClass), true);
// Process any @ImportResource annotations
//解析@ImportResource配置类
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
//处理@Bean注解修饰的类
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
// 处理接口中的默认方法
processInterfaces(configClass, sourceClass);
// Process superclass, if any
//如果该类有父类,则继续返回,上层方法判断不为空,则继续递归执行
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
11、查看获取配置类的逻辑
processImports(configClass, sourceClass, getImports(sourceClass), true);
/**
* Returns {@code @Import} class, considering all meta-annotations.
*/
private Set<SourceClass> getImports(SourceClass sourceClass) throws IOException {
Set<SourceClass> imports = new LinkedHashSet<>();
Set<SourceClass> visited = new LinkedHashSet<>();
collectImports(sourceClass, imports, visited);
return imports;
}
------------------
/**
* Recursively collect all declared {@code @Import} values. Unlike most
* meta-annotations it is valid to have several {@code @Import}s declared with
* different values; the usual process of returning values from the first
* meta-annotation on a class is not sufficient.
* <p>For example, it is common for a {@code @Configuration} class to declare direct
* {@code @Import}s in addition to meta-imports originating from an {@code @Enable}
* annotation.
* 看到所有的bean都以导入的方式被加载进去
*/
private void collectImports(SourceClass sourceClass, Set<SourceClass> imports, Set<SourceClass> visited)
throws IOException {
if (visited.add(sourceClass)) {
for (SourceClass annotation : sourceClass.getAnnotations()) {
String annName = annotation.getMetadata().getClassName();
if (!annName.equals(Import.class.getName())) {
collectImports(annotation, imports, visited);
}
}
imports.addAll(sourceClass.getAnnotationAttributes(Import.class.getName(), "value"));
}
}
12、继续回到ConfigurationClassParser中的parse方法中的最后一行,继续跟进该方法:
this.deferredImportSelectorHandler.process()
-------------
public void process() {
List<DeferredImportSelectorHolder> deferredImports = this.deferredImportSelectors;
this.deferredImportSelectors = null;
try {
if (deferredImports != null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
deferredImports.sort(DEFERRED_IMPORT_COMPARATOR);
deferredImports.forEach(handler::register);
handler.processGroupImports();
}
}
finally {
this.deferredImportSelectors = new ArrayList<>();
}
}
---------------
public void processGroupImports() {
for (DeferredImportSelectorGrouping grouping : this.groupings.values()) {
grouping.getImports().forEach(entry -> {
ConfigurationClass configurationClass = this.configurationClasses.get(
entry.getMetadata());
try {
processImports(configurationClass, asSourceClass(configurationClass),
asSourceClasses(entry.getImportClassName()), false);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configurationClass.getMetadata().getClassName() + "]", ex);
}
});
}
}
------------
/**
* Return the imports defined by the group.
* @return each import with its associated configuration class
*/
public Iterable<Group.Entry> getImports() {
for (DeferredImportSelectorHolder deferredImport : this.deferredImports) {
this.group.process(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getImportSelector());
}
return this.group.selectImports();
}
}
------------
public DeferredImportSelector getImportSelector() {
return this.importSelector;
}
------------
@Override
public void process(AnnotationMetadata annotationMetadata, DeferredImportSelector deferredImportSelector) {
Assert.state(deferredImportSelector instanceof AutoConfigurationImportSelector,
() -> String.format("Only %s implementations are supported, got %s",
AutoConfigurationImportSelector.class.getSimpleName(),
deferredImportSelector.getClass().getName()));
AutoConfigurationEntry autoConfigurationEntry = ((AutoConfigurationImportSelector) deferredImportSelector)
.getAutoConfigurationEntry(getAutoConfigurationMetadata(), annotationMetadata);
this.autoConfigurationEntries.add(autoConfigurationEntry);
for (String importClassName : autoConfigurationEntry.getConfigurations()) {
this.entries.putIfAbsent(importClassName, annotationMetadata);
}
}
48.什么是嵌入式服务器,为什么使用嵌入式服务器?
在springboot框架中,大家应该发现了有一个内嵌的tomcat,在之前的开发流程中,每次写好代码之后必须要将项目部署到一个额外的web服务器中,只有这样才可以运行,这个明显要麻烦很多,而使用springboot的时候,你会发现在启动项目的时候可以直接按照java应用程序的方式来启动项目,不需要额外的环境支持,也不需要tomcat服务器,这是因为在springboot框架中内置了tomcat.jar,来通过main方法启动容器,达到一键开发部署的方式,不需要额外的任何其他操作。
49.Spring中的事务是如何实现的
Spring事务底层是基于数据库事务和AOP机制的
⾸先对于使⽤了@Transactional注解的Bean,Spring会创建⼀个代理对象作为Bean
当调⽤代理对象的⽅法时,会先判断该⽅法上是否加了@Transactional注解
如果加了,那么则利⽤事务管理器创建⼀个数据库连接
并且修改数据库连接的autocommit属性为false,禁⽌此连接的⾃动提交,这是实现Spring事务⾮常重要的⼀步
然后执⾏当前⽅法,⽅法中会执⾏sql
执⾏完当前⽅法后,如果没有出现异常就直接提交事务
如果出现了异常,并且这个异常是需要回滚的就会回滚事务,否则仍然提交事务
Spring事务的隔离级别对应的就是数据库的隔离级别
Spring事务的传播机制是Spring事务⾃⼰实现的,也是Spring事务中最复杂的
Spring事务的传播机制是基于数据库连接来做的,⼀个数据库连接⼀个事务,如果传播机制配置为需要新开⼀个事务,那么实际上就是先建⽴⼀个数据库连接,在此新数据库连接上执⾏sql
50.Spring启动流程
在创建Spring容器,也就是启动Spring时,⾸先会进⾏扫描,扫描得到所有的BeanDefinition对象,并存在⼀个Map中
然后筛选出⾮懒加载的单例BeanDefinition进⾏创建Bean,对于多例Bean不需要在启动过程中去进⾏创建,对于多例Bean会在每次获取Bean时利⽤BeanDefinition去创建
利⽤BeanDefinition创建Bean就是Bean的创建⽣命周期,这期间包括了合并BeanDefinition、推断 构造⽅法、实例化、属性填充、初始化前、初始化、初始化后等步骤,其中AOP就是发⽣在初始化后这⼀步骤中
单例Bean创建完了之后,Spring会发布⼀个容器启动事件
Spring启动结束
在源码中会更复杂,⽐如源码中会提供⼀些模板⽅法,让⼦类来实现,⽐如源码中还涉及到⼀些 BeanFactoryPostProcessor和BeanPostProcessor的注册,Spring的扫描就是通过BenaFactoryPostProcessor来实现的,依赖注⼊就是通过BeanPostProcessor来实现的
BenaFactoryPostProcessor来实现的,依赖注⼊
51.Spring Boot中配置⽂件的加载顺序是怎样的?
优先级从⾼到低,⾼优先级的配置覆盖低优先级的配置,所有配置会形成互补配置。
命令⾏参数。所有的配置都可以在命令⾏上进⾏指定;
Java系统属性(System.getProperties());
操作系统环境变量 ;
jar包外部的application-{profile}.properties或application.yml(带spring.profile)配置⽂件
jar包内部的application-{profile}.properties或application.yml(带spring.profile)配置⽂件 再来加载不带profile
jar包外部的application.properties或application.yml(不带spring.profile)配置⽂件
jar包内部的application.properties或applicatio.yml
52.延迟加载
默认情况下,容器启动之后会将所有作用域为单例的 Bean 都创建好,但是有的业务场景我们并不需要它提前都创建好。此时,我们可以在Bean 中设置 lzay-init = "true" 。
- 这样,当容器启动之后,作用域为单例的 Bean ,就不在创建。
- 而是在获得该 Bean 时,才真正在创建加载。
53.@RestController 和 @Controller 有什么区别?
@RestController 注解,在 @Controller 基础上,增加了 @ResponseBody 注解,更加适合目前前后端分离的架构下,提供 Restful API ,返回例如 JSON 数据格式。
54.@RequestMapping 注解有什么用?
@RequestMapping 注解,用于将特定 HTTP 请求方法映射到将处理相应请求的控制器中的特定类/方法。此注释可应用于两个级别:
- 类级别:映射请求的 URL。
- 方法级别:映射 URL 以及 HTTP 请求方法。
55.@RequestMapping 和 @GetMapping 注解的不同之处在哪里?
@RequestMapping可注解在类和方法上;@GetMapping仅可注册在方法上。@RequestMapping可进行 GET、POST、PUT、DELETE 等请求方法;@GetMapping是@RequestMapping的 GET 请求方法的特例,目的是为了提高清晰度。
56.Spring 中有哪些方式可以把 Bean 注入 到 IOC 容器?
使用@CompontScan 注解来扫描声明了@Controller、@Service、@Repository、 @Component 注解的类。
使用@Configuration 注解声明配置类,并使用@Bean 注解实现 Bean 的定义, 这种方式其实是 xml 配置方式的一种演变,是 Spring 迈入到无配置化时代的里 程碑。
使用@Import 注解,导入配置类或者普通的 Bean
使 用 FactoryBean 工 厂 bean , 动 态 构 建 一 个 Bean 实 例 , Spring Cloud OpenFeign 里面的动态代理实例就是使用 FactoryBean 来实现的。
实现 ImportBeanDefinitionRegistrar 接口, 可以动态注入 Bean 实例。 这个在 Spring Boot 里面的启动注解有用到。
实现 ImportSelector 接口,动态批量注入配置类或者 Bean 对象,这个在 Spring Boot 里面的自动装配机制里面有用到。
57.Spring 中 BeanFactory 和 FactoryBean 的区别
首先,Spring 里面的核心功能是 IOC 容器,所谓 IOC 容器呢,本质上就是一个 Bean 的容器或者是一个 Bean 的工厂。 它能够根据 xml 里面声明的 Bean 配置进行 bean 的加载和初始化, 然后 BeanFactory 来生产我们需要的各种各样的 Bean。 所以我对 BeanFactory 的理解了有两个。
BeanFactory 是所有 Spring Bean 容器的顶级接口,它为 Spring 的容器定义了 一套规范,并提供像 getBean 这样的方法从容器中获取指定的 Bean 实例。
BeanFactory 在产生 Bean 的同时,还提供了解决 Bean 之间的依赖注入的能力, 也就是所谓的 DI。
FactoryBean 是一个工厂 Bean,它是一个接口,主要的功能是动态生成某一个类型的 Bean 的实例,也就是说,我们可以自定义一个 Bean 并且加载到 IOC 容 器里面。
它里面有一个重要的方法叫 getObject() , 这个方法里面就是用来实现动态构建 Bean 的过程。 Spring Cloud 里 面 的 OpenFeign 组 件 , 客 户 端 的 代 理 类 , 就 是 使 用 了 FactoryBean 来实现的。
58.介绍下 Spring IoC 的工作流程
IOC 的全称是 Inversion Of Control,也就是控制反转,它的核心思想是把对象的管理权限交给容器。 应用程序如果需要使用到某个对象实例,直接从 IOC 容器中去获取就行,这样设计的好处是降低了程序里面对象与对象之间的耦合性。 使得程序的整个体系结构变得更加灵活。
Spring 里面很多方式去定义 Bean, 比如 XML 里面的标签、@Service、 @Component、@Repository、@Configuration 配置类中的@Bean 注解等等。 Spring 在启动的时候,会去解析这些 Bean 然后保存到 IOC 容器里面。
Spring IOC 的工作流程大致可以分为两个阶段。
第一个阶段,就是 IOC 容器的初始化这个阶段主要是根据程序中定义的 XML 或者注解等 Bean 的声明方式 通过解析和加载后生成 BeanDefinition, 然后把 BeanDefinition 注册到 IOC 容 器。
通过注解或者 xml 声明的 bean 都会解析得到一个 BeanDefinition 实体,实体中包含这个 bean 中定义的基本属性。 最后把这个 BeanDefinition 保存到一个 Map 集合里面,从而完成了 IOC 的初始 化。 IoC 容器的作用就是对这些注册的 Bean 的定义信息进行处理和维护,它 IoC 容 器控制反转的核心。
第二个阶段,完成 Bean 初始化及依赖注入 然后进入到第二个阶段,这个阶段会做两个事情
通过反射针对没有设置 lazy-init 属性的单例 bean 进行初始化。
完成 Bean 的依赖注入。
第三个阶段, Bean 的使用 通常我们会通过@Autowired 或者 BeanFactory.getBean()从 IOC 容器中获取指 定的 bean 实例。 另外,针对设置 layy-init 属性以及非单例 bean 的实例化,是在每次获取 bean 对象的时候,调用 bean 的初始化方法来完成实例化的,并且 Spring IOC 容器 不会去管理这些 Bean。
59.过滤器、拦截器、AOP的区别
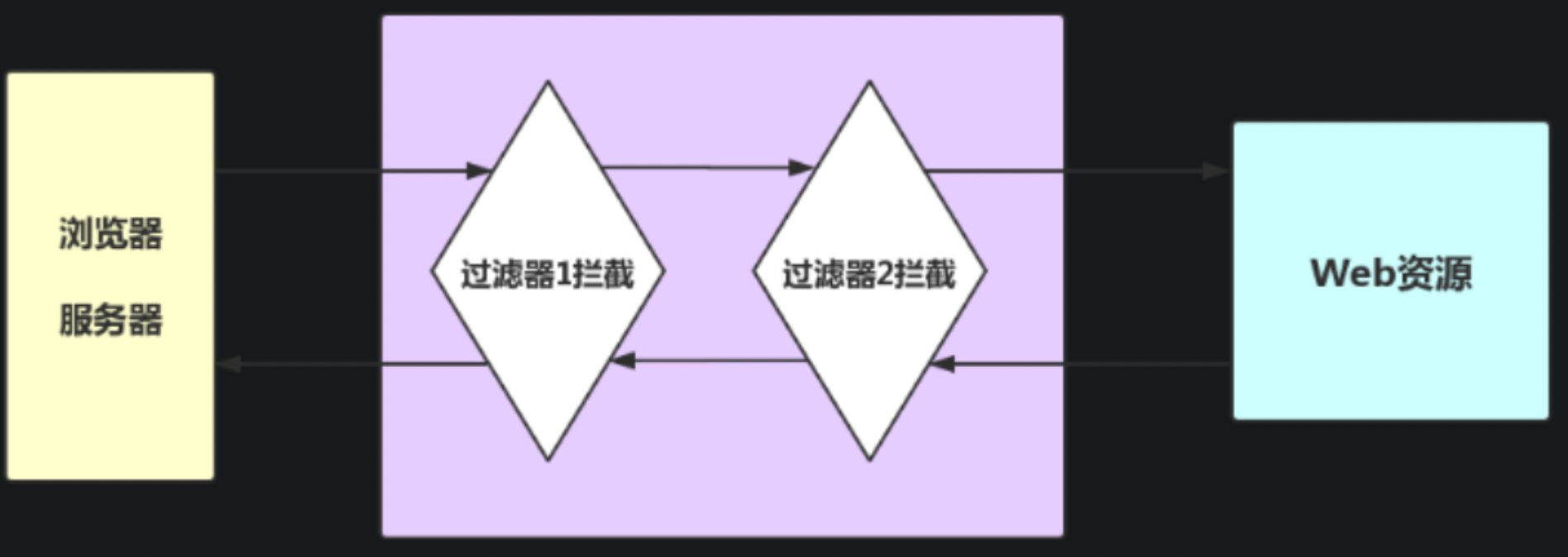
- 什么是过滤器(Filter) 过滤器,顾名思义就是起到过滤筛选作用的一种事物,只不过相较于现实生活中的过滤器,这里的过滤器过滤的对象是客户端访问的web资源,也可以理解为一种预处理手段,对资源进行拦截后,将其中我们认为的杂质(用户自己定义的)过滤,符合条件的放行,不符合的则拦截下来。
1.1 过滤器常见的使用场景
- 统一设置编码
- 过滤敏感字符
- 登录校验
- URL级别的访问权限控制
- 数据压缩
1.2 Springboot 整合过滤器
Bean注入方式
编写Filter
public class HeFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {
System.out.println("您已进入filter过滤器,您的请求正常,请继续遵规则...");
chain.doFilter(request, response);
}
@Override
public void destroy() {
}
}
编写Filter配置类
@Configuration
public class ServletConfig {
@Bean
public FilterRegistrationBean heFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean(new HeFilter());
registration.addUrlPatterns("/*");
return registration;
}
}
注解方式
@Slf4j
@Component
// filterName就是当前类名称,还有一个urlPattens的参数,这个参数表示要过滤的URL上的后缀名,是多参数,可以用数组表示。
@WebFilter(value = "/hello") 或 (filterName = "f1", urlPatterns = {"*.html","*.jsp","/hello"})
public class HelloFilter2 implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
log.info("进入到过滤器2啦");
// 这里可以进行一些条件判断(假如要做登录验证的话)
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
}
}
在主启动类上加@ServletComponentScan(“com.pandy.blog.filters”) 指明filter所在位置的包。 若有多个filter,默认根据filter类名的字母倒叙排列,且@WebFilter注解方式的过滤器优先级高于Bean注入方式配置的过滤器。
1.3 过滤器(Filter)详解
a) Filter是依赖于Servlet的,需要有Servlet的依赖。
b) init() 在容器初始化时执行,只执行一次。
c) doFilter() 目标请求之前拦截执行,拦截之后需要放行才开始执行目标方法。filterChain.doFilter(servletRequest,servletResponse);
d) destroy() 在容器销毁时执行,只执行一次。
e) Filter可以拦截所有请求。包括静态资源[css,js…]。
f) 基于函数回调实现。
g) 过滤器只能在容器初始化时被调用一次。
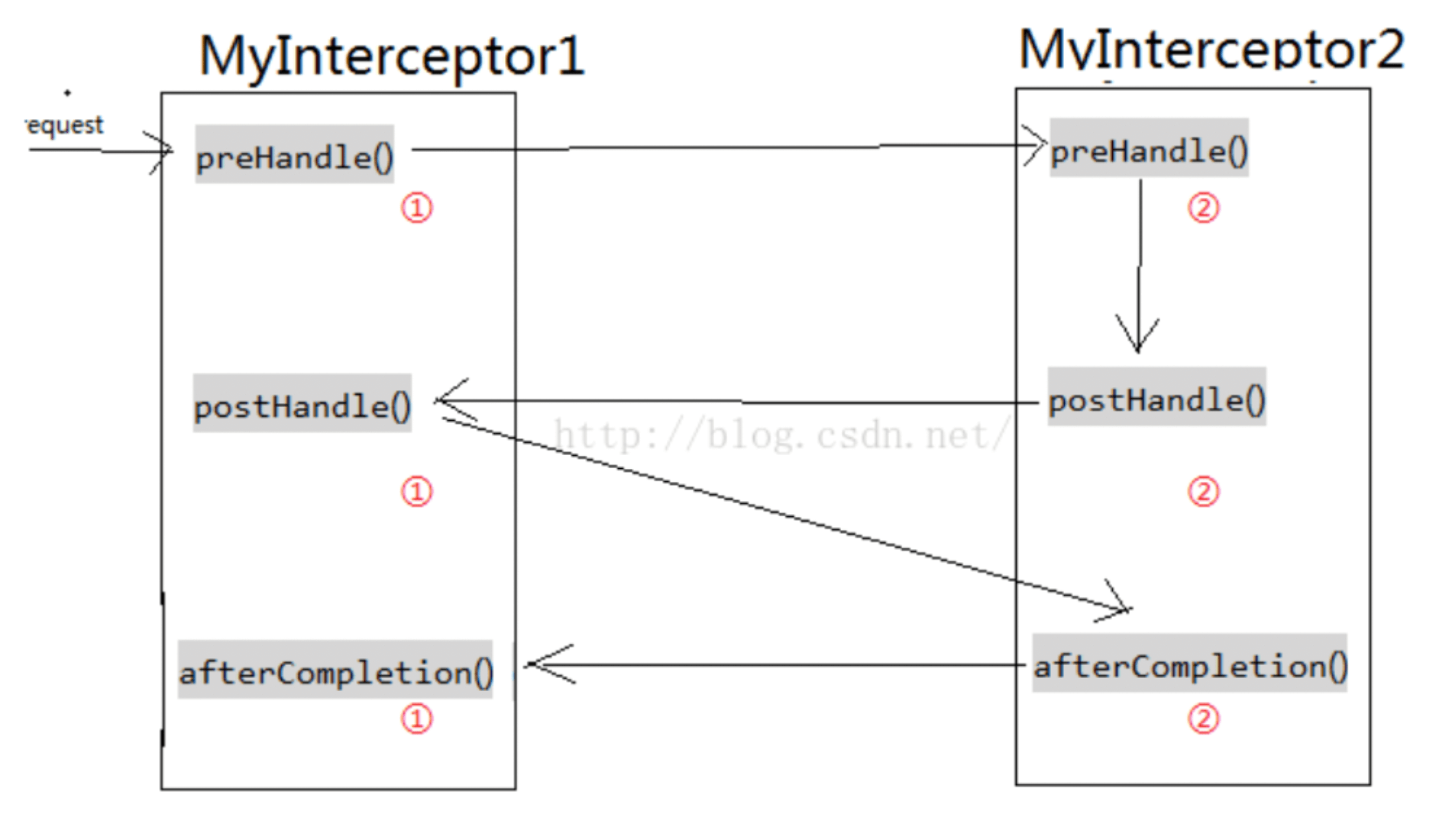
- 什么是拦截器(Interceptor)
拦截器是springmvc提供的,类似于过滤器。主要用于拦截用户请求并作相应的处理。
2.1 拦截器的使用场景
a) 日志记录
b) 权限校验
c) 登录校验
d) 性能检测[检测方法的执行时间]
其实拦截器和过滤器很像,有些使用场景。无论选用谁都能实现。需要注意的使他们彼此的使用范围,触发机制。
2.2 springboot整合拦截器
- 编写自定义拦截器类实现HandlerInterceptor接口或继承其子类【推荐实现的方式,实现可以自动生成preHandle…】
@Component
public class InterceptorDemo implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截器preHandle在控制器方法执行前执行");
//true:表示放行
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("拦截器postHandle在控制器方法执行后执行");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("拦截器afterCompletion在请求完成后执行");
}
}
- 基于springmvc编写配置类
@Configuration
// 老版本呢是继承WebMvcConfigurerAdapter不过新版本已经放弃了,推荐用下面的方式。
public class InterceptorConfig implements WebMvcConfigurer {
@Autowired
private InterceptorDemo interceptorDemo;
@Override
public void addInterceptors(InterceptorRegistry registry) {
// ** 表示所有拦截路径
registry.addInterceptor(interceptorDemo).addPathPatterns("/**");
// 或下面这种写法 【若编写自定义拦截器类没有加@Component注解】
registry.addInterceptor(new InterceptorDemo()).addPathPatterns("/**");
}
}
2.3 拦截器详情 a) 拦截器是依赖于SpringMVC的,需要有mvc的依赖。
b) preHandle() 在目标请求完成之前执行。有返回值Boolean类型,true:表示放行
c) postHandle() 在目标请求之完成后执行。
d) afterCompletion() 在整个请求完成之后【modelAndView已被渲染执行】。
e) 拦截器只能拦截action请求。不包括静态资源==[css,js…]==。
f) 基于java反射机制实现。
g) 在拦截器的生命周期中,可以多次被调用。
关于拦截器的preHandle()方法的参数说明:
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler){
}
@param request current HTTP request
@param response current HTTP response
@param handler chosen handler to execute, for type and/or instance evaluation //选择要执行的处理程序,用于类型和/或实例计算
- 拦截器与过滤器的区别
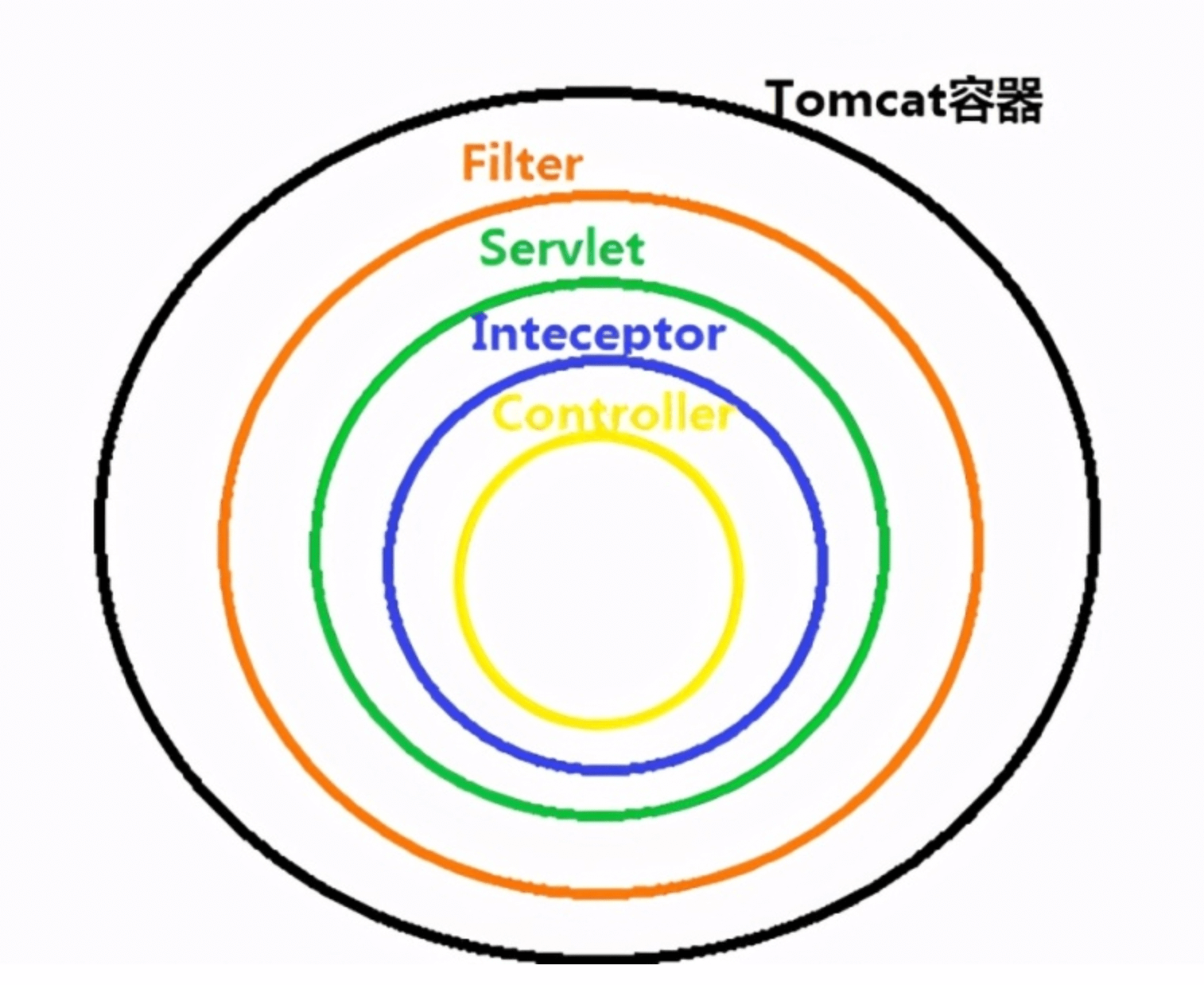
1、过滤器和拦截器触发时机不一样,过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的。请求结束返回也是,是在servlet处理完后,返回给前端之前。
2、拦截器可以获取IOC容器中的各个bean,而过滤器就不行,因为拦截器是spring提供并管理的,spring的功能可以被拦截器使用,在拦截器里注入一个service,可以调用业务逻辑。而过滤器是JavaEE标准,只需依赖servlet api ,不需要依赖spring。
3、过滤器的实现基于回调函数。而拦截器(代理模式)的实现基于反射
4、Filter是依赖于Servlet容器,属于Servlet规范的一部分,而拦截器则是独立存在的,可以在任何情况下使用。
5、Filter的执行由Servlet容器回调完成,而拦截器通常通过动态代理(反射)的方式来执行。
6、Filter的生命周期由Servlet容器管理,而拦截器则可以通过IoC容器来管理,因此可以通过注入等方式来获取其他Bean的实例,因此使用会更方便。
7、拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用(包括静态资源)。
【重点】过滤器和拦截器非常相似,但是它们有很大的区别:
最简单明了的区别就是过滤器可以修改request,而拦截器不能
过滤器需要在servlet容器中实现,拦截器可以适用于javaEE,javaSE等各种环境
拦截器可以调用IOC容器中的各种依赖,而过滤器不能
过滤器只能在请求的前后使用,而拦截器可以详细到每个方法
当有过滤器和拦截器时的执行流程: 
链接: https://mp.weixin.qq.com/s/cgAkz7f2uRJURnzr9LSjkA
4.AOP与过滤器、拦截器的区别
过滤器,拦截器拦截的是URL。AOP拦截的是类的元数据(包、类、方法名、参数等)。
过滤器并没有定义业务用于执行逻辑前、后等,仅仅是请求到达就执行。
拦截器有三个方法,相对于过滤器更加细致,有被拦截逻辑执行前、后等。 AOP针对具体的代码,能够实现更加复杂的业务逻辑。
三者功能类似,但各有优势,从过滤器–》拦截器–》切面,拦截规则越来越细致。 执行顺序依次是过滤器、拦截器、切面。
三者的使用场景
在编写相对比较公用的代码时,优先考虑过滤器,然后是拦截器,最后是aop。
比如:
权限校验,一般情况下,所有的请求都需要做登陆校验,此时就应该使用过滤器在最顶层做校验;
日志记录,一般日志只会针对部分逻辑做日志记录,而且牵扯到业务逻辑完成前后的日志记录,因此使用过滤器不能细致地划分模块,此时应该考虑拦截器,
然而拦截器也是依据URL做规则匹配,因此相对来说不够细致,因此我们会考虑到使用AOP实现,AOP可以针对代码的方法级别做拦截,很适合日志功能。
60.什么情况下会导致@Async异步方法会失效?
1.不要在本类中异步调用。即一个方法是异步方法,然后用另一个方法调用这个异步方法。
2.不要有返回值,使用void
3.不能使用本类的私有方法或者非接口化加注@Async,因为代理不到失效
4.异步方法不能使用static修饰
5.异步类需使用@Component注解,不然将导致spring无法扫描到异步类
6.SpringBoot框架必须在启动类中增加@EnableAsync注解
7.异步方法不要和事物注解同时存在。可以在事物的方法中调用另外一个类中的异步方法。在调用Async方法的方法上标注@Transactional是管理调用方法的事务的,在Async方法上标注@Transactional是管理异步方法的事务,事务因线程隔离
8.诸如以上几点的情况比如spring中的@Transactional还有cache注解也不能有以上几点情况,否则也会失效的,因为本质都是因为代理的机制导致的
61.spring与springboot默认aop采用?
Spring 5.x 中 AOP 默认依旧使用 JDK 动态代理。 SpringBoot 2.x 开始,为了解决使用 JDK 动态代理可能导致的类型转化异常而默认使用 CGLIB。 在 SpringBoot 2.x 中,如果需要默认使用 JDK 动态代理可以通过配置项spring.aop.proxy-target-class=false来进行修改,proxyTargetClass配置已无效。
62.介绍下Spring的初始化过程
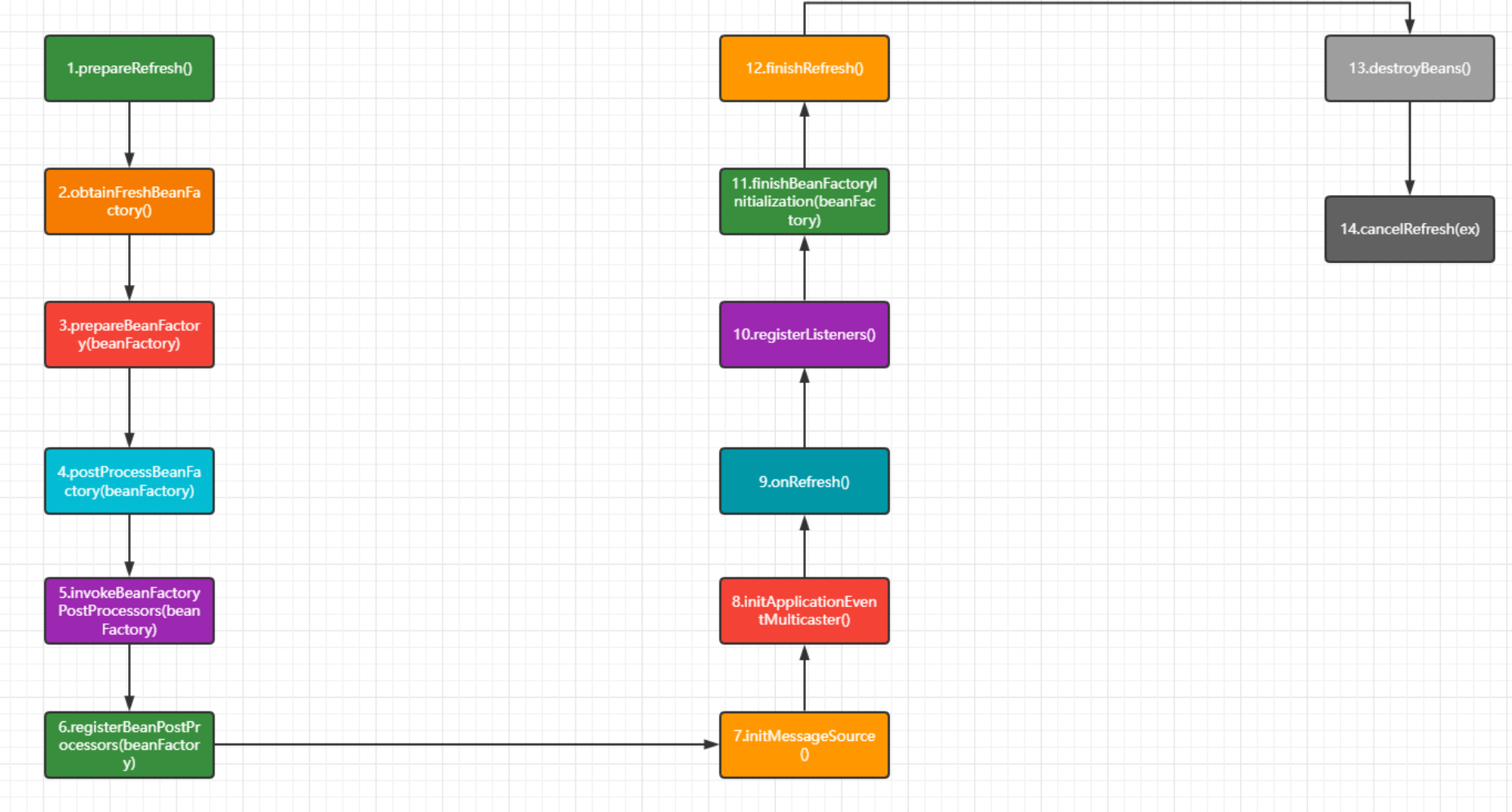
每个方法的相关作用
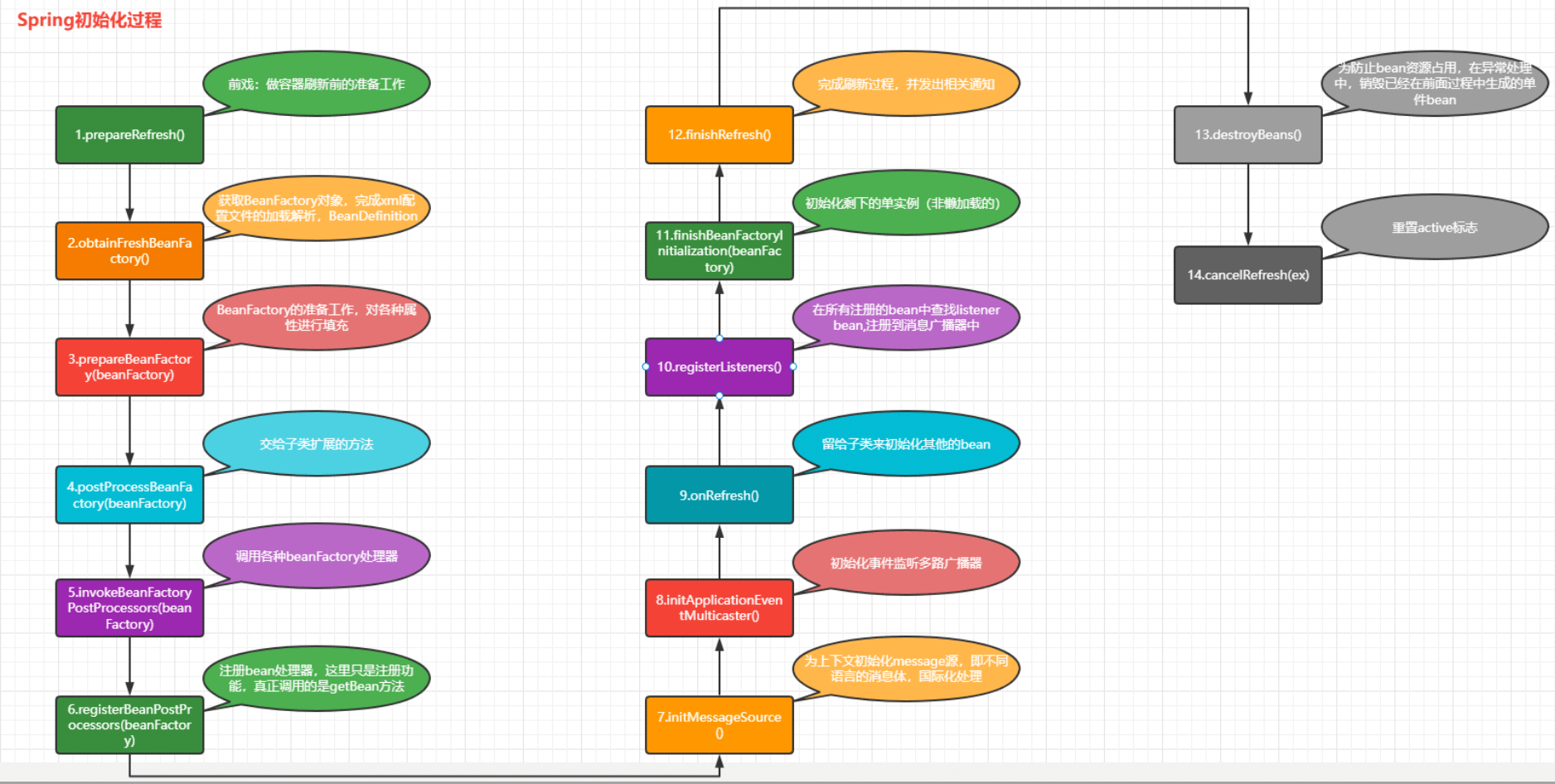
63.配置文件的加载解析
Spring初始化的时候在obtainFreshBeanFactory方法中完成了配置文件的加载解析,并把解析的bean标签信息封装到了BeanDefinition对象中,所有的解析的BeanDefinition对象都存储在了DefaultListableBeanFactory对象的beanDefinitionMap的Map集合中。
64.介绍下Spring中常用的注解
@Import注解本身的由来是在Spring3.0的时候由xml文件的方式向注解编程的发展,替换以前在配置文件中的/
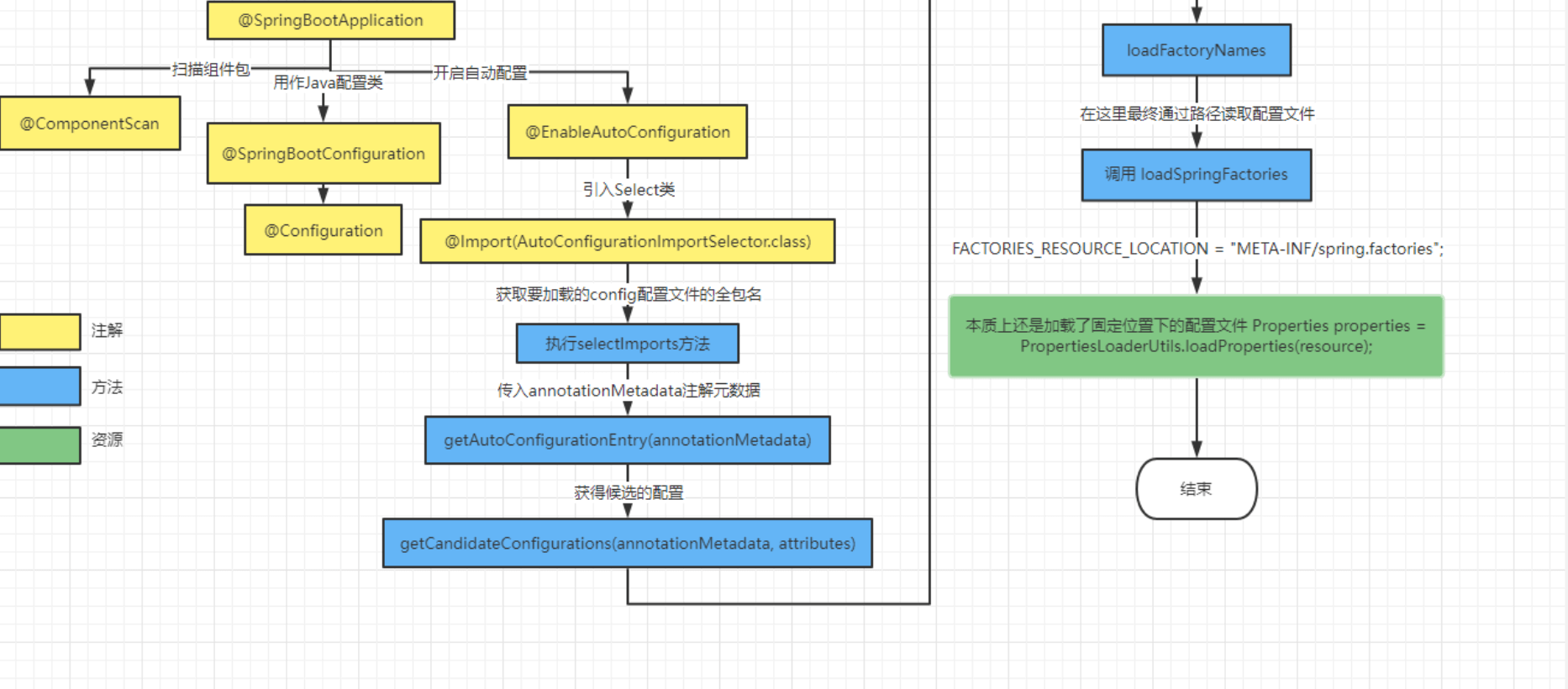
<import>标签,也就是可以导入其他的配置类,然后@Import注解还扩展了对应的功能静态注入:可以直接把对应的类型注入到容器中:@Import(User.class) 动态注入:可以实现ImportSelector接口和ImportBeanDefinitionRegistrar接口,然后通过重写对应的方法来实现动态的注入 当然在ImportSelector接口的实现还可以触发延迟加载的逻辑。DeferredImportSelector,这块在SpringBoot的自动装配中就应用到了@indexed注解。默认所有的@compoent注解都加了indexed注解,用于加快索引组件。
65.SpringBoot 的自动装配原理
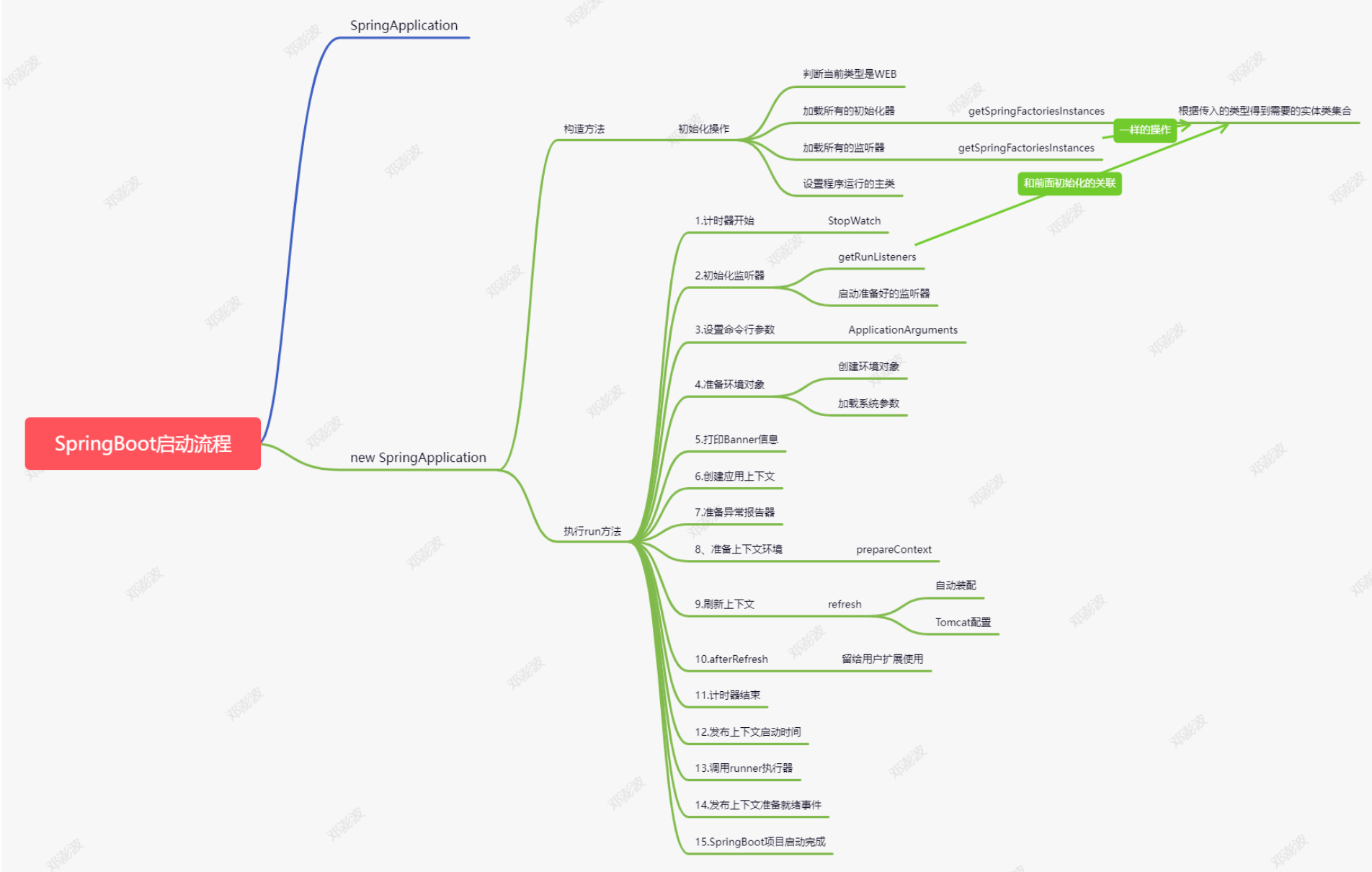
66.介绍下SpringBoot的启动流程
67.Spring 只处理单例模式下得循环依赖?
- 对于单例( Singleton )模式, Spring 在创建 Bean 的时候并不是等 Bean 完全创建完成后才会将 Bean 添加至缓存中,而是不等 Bean 创建完成就会将创建 Bean 的 ObjectFactory 提早加入到缓存中,这样一旦下一个 Bean 创建的时候需要依赖 bean 时则直接使用 ObjectFactroy 。
- 但是原型( Prototype )模式,我们知道是没法使用缓存的,所以 Spring 对原型模式的循环依赖处理策略则是不处理。
68.Last-Modified缓存机制?
Spring MVC 支持HTTP协议的 Last-Modified 缓存机制。
在客户端地一次输入URL时,服务器端会返回内容和状态码200, 表示请求成功,同时会添加一个“Last-Modified”属性,表示该请求资源的最后修改时间。
客户端第二次请求此URL时,客户端会向服务器发送请求头 “IF-Modified-Since”,如果服务端内容没有变化,则自动返回HTTP304状态码(只返回相应头信息,不返回资源文件内容,这样就可以节省网络带宽,提供响应速度和用户体验)
#DispatcherServlet.doDispatch()首先获取 http 请求的method type。如果method 是 “GET”或“HEAD” 才支持缓存机制