SqlNode (动态SQL脚本)
SqlNode (动态SQL脚本)
动态SQL xml元素最终都会被解成一个可执行的脚本。而MyBatis 正是通过为这个脚本传递参数,并执行脚本计算来生成动态SQL。脚本在MyBatis中体现即SqlNode。首先Mybatis中使用了OGNL表达式对条件进行判断,然后采用解释器模式,对整个动态sql的语法树进行处理,最后形成了需要执行的BoundSql对象。
/**
* 一次可执行的 SQL 封装
*
* @author Clinton Begin
*/
public class BoundSql {
/**
* 可执行的 SQL 语句
*/
private final String sql;
/**
* 参数映射
*/
private final List<ParameterMapping> parameterMappings;
/**
* 原始参数对象
*/
private final Object parameterObject;
/**
* 对动态参数运算后的新参数
*/
private final Map<String, Object> additionalParameters;
/**
* 操作原始参数的MetaObject
*/
private final MetaObject metaParameters;
public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.parameterObject = parameterObject;
this.additionalParameters = new HashMap<>();
this.metaParameters = configuration.newMetaObject(additionalParameters);
}
public String getSql() {
return sql;
}
public List<ParameterMapping> getParameterMappings() {
return parameterMappings;
}
public Object getParameterObject() {
return parameterObject;
}
public boolean hasAdditionalParameter(String name) {
String paramName = new PropertyTokenizer(name).getName();
return additionalParameters.containsKey(paramName);
}
public void setAdditionalParameter(String name, Object value) {
metaParameters.setValue(name, value);
}
public Object getAdditionalParameter(String name) {
return metaParameters.getValue(name);
}
}

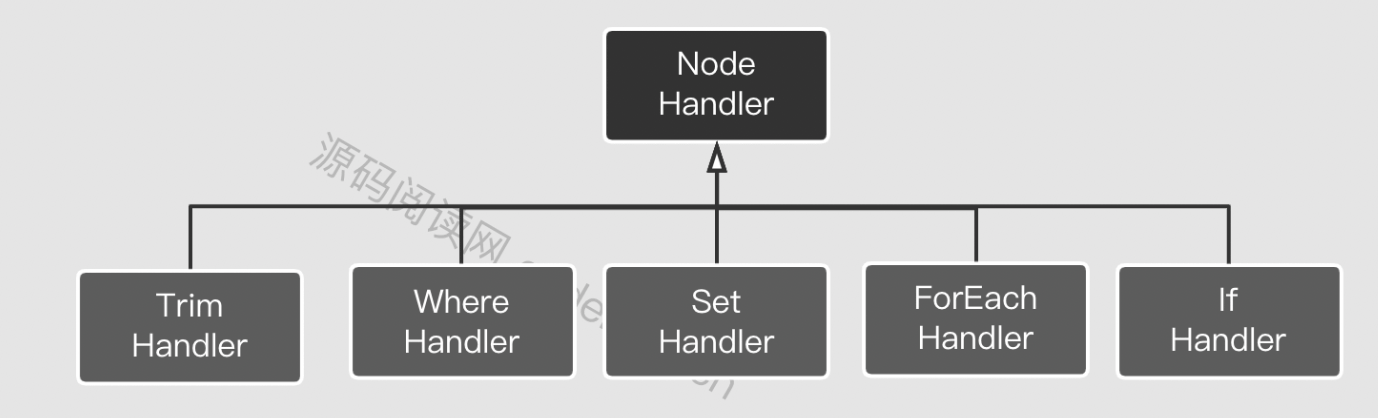
每个动态元素都会有一个与之对应的脚本类。 SqlNode主要使用解释器模式,对每隔标签进行实现:如if 对应ifSqlNode、forEarch对应ForEachSqlNode 以此类推下去。这里要注意下面三个脚本。
StaticTextSqlNode表示一段纯静态文本如:select * from userTextSqlNode表示一个通过参数拼装的文本如:select * from ${user}MixedSqlNode表示多个节点的集合
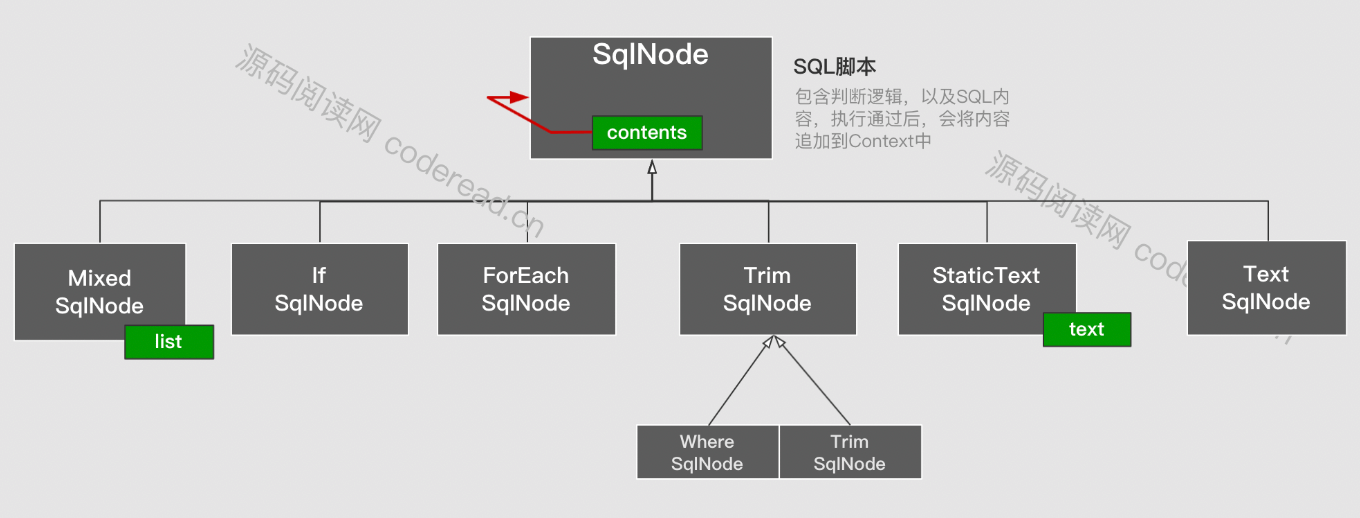
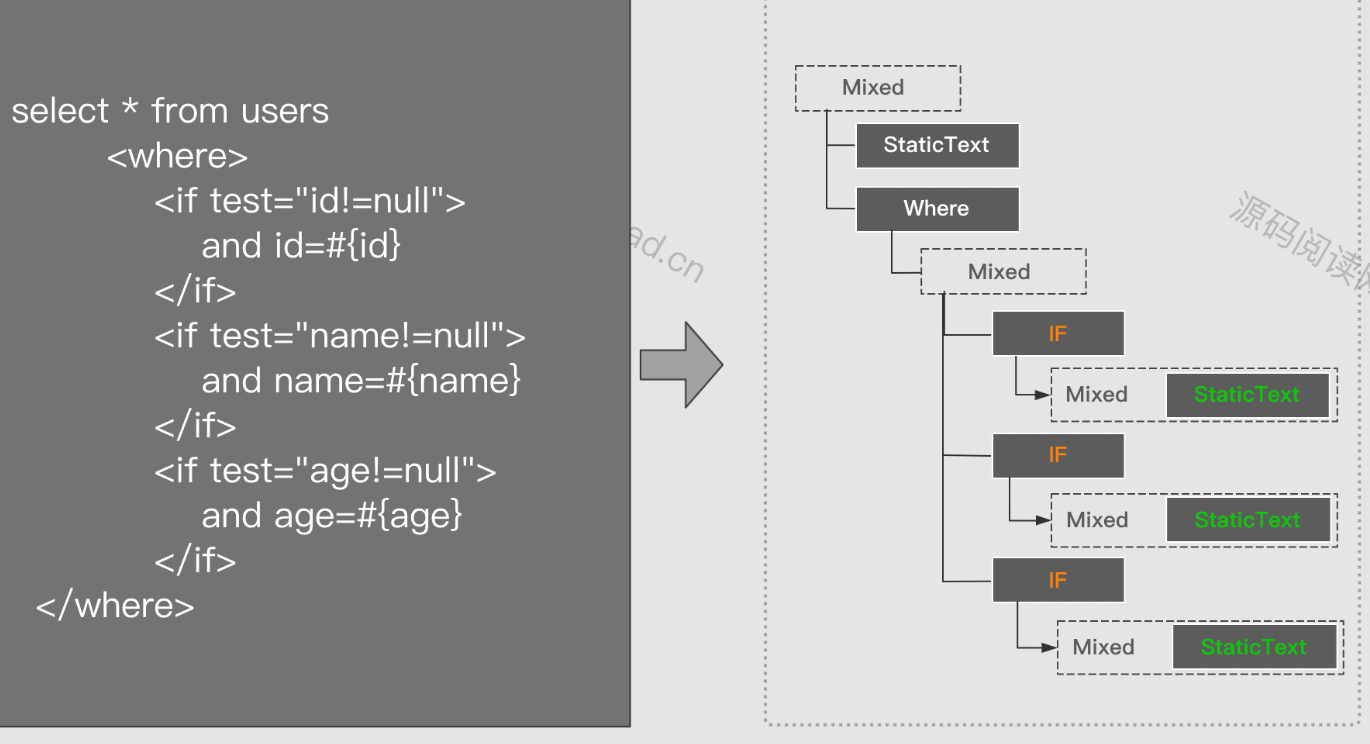
脚本之间是呈现嵌套关系的。比如if元素中会包含一个MixedSqlNode ,而MixedSqlNode下又会包含1至1至多个其它节点。最后组成一课脚本语法树。如下面左边的SQL元素组成右边的语法树。在节点最底层一定是一个StaticTextNode或 TextNode
SqlNode的接口非常简单,就只有一个apply方法,方法的作用就是执行当前脚本节点逻辑,并把结果应用到DynamicContext当中去。
public interface SqlNode {
boolean apply(DynamicContext context);
}
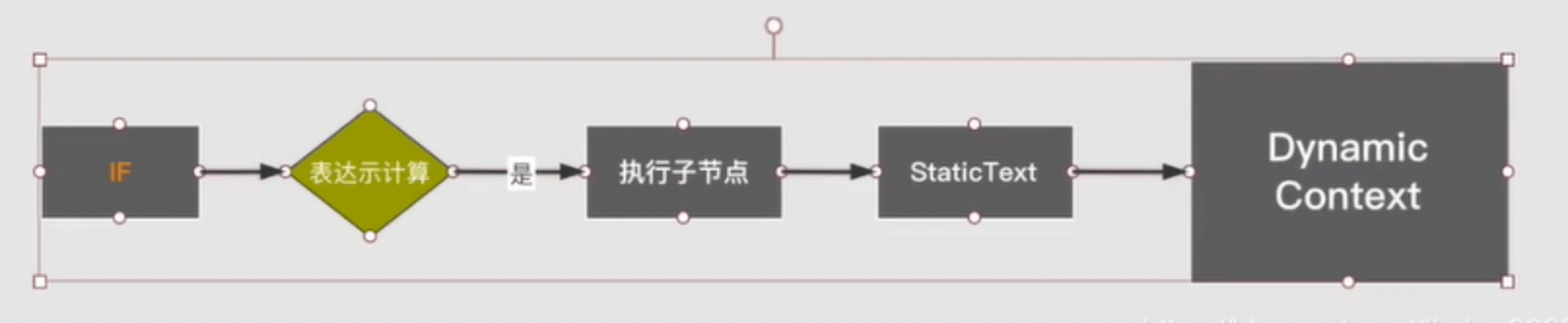
如IfSqlNode当中执行 apply时先计算If逻辑,如果通过就会继续去访问它的子节点。直到最后访问到TextNode 时把SQL文本添加至DynamicContext。 通过这种类似递归方式Context就会访问到所有的的节点,并把最后最终符合条件的的SQL文本追加到 Context中。
//IfSqlNode
public boolean apply(DynamicContext context) {//计算if表达示
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
//StaticTextSqlNode
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}

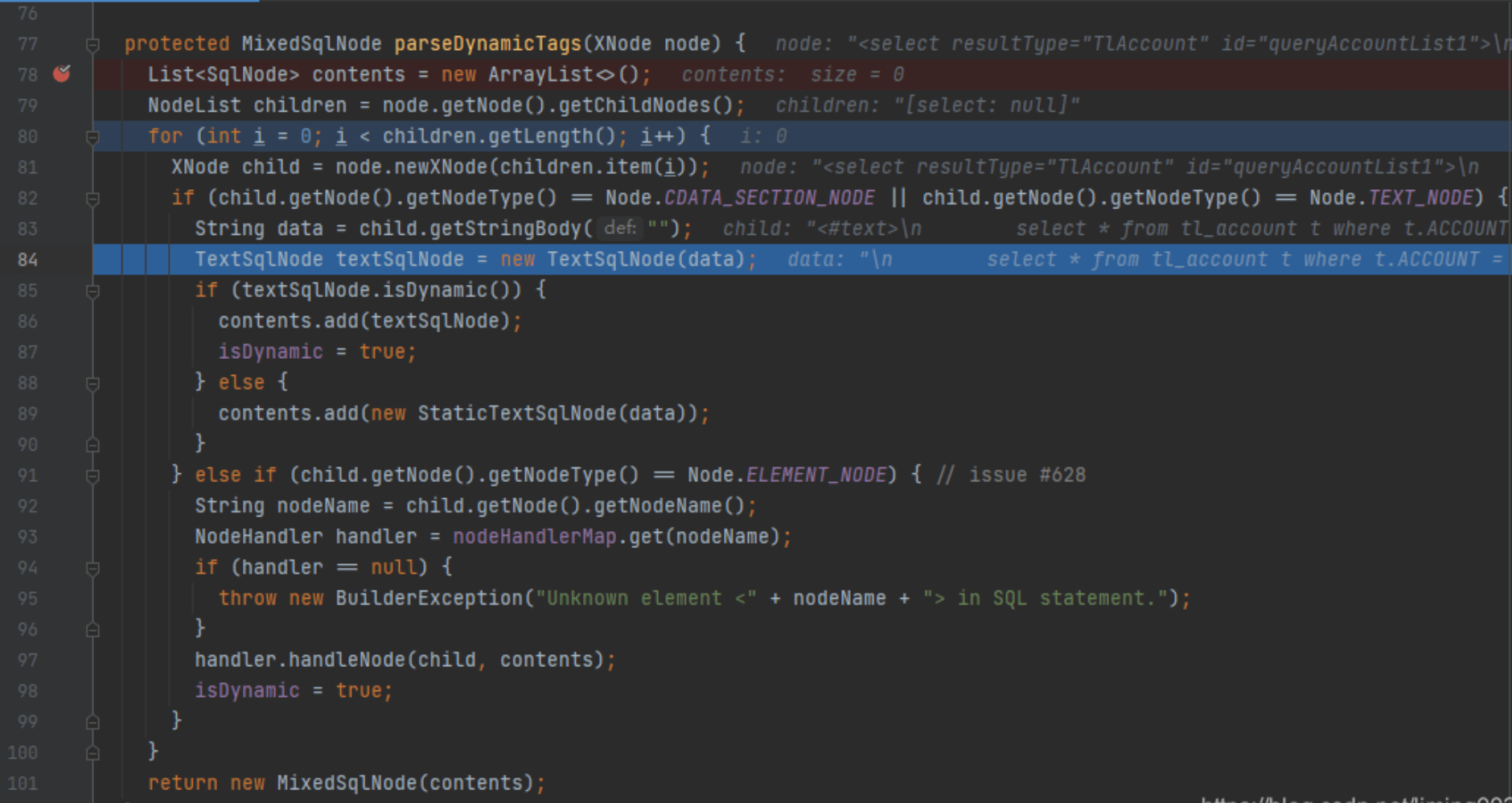
访问完所有节点之后,就会生成一个SQL字符串,但这个并不是可直接执行的SQL,因为里面的参数还是表达式的形式#{name=name} 就需要通过SqlSourceBuilder 来构建可执行的SQL和参数映射ParameterMapping 。然后才能生成BoundSql。下图表示了在上下文中执行所有节点之后,最生成BoundSql。

SqlSource(SQL数据源)
在上层定义上每个Sql映射(MappedStatement)中都会包含一个SqlSource 用来获取可执行Sql(BoundSql)。SqlSource又分为原生SQL源与动态SQL源,以及第三方源。脚本的解析流程:把XML -> SqlSource -> BoundSql 的过程。
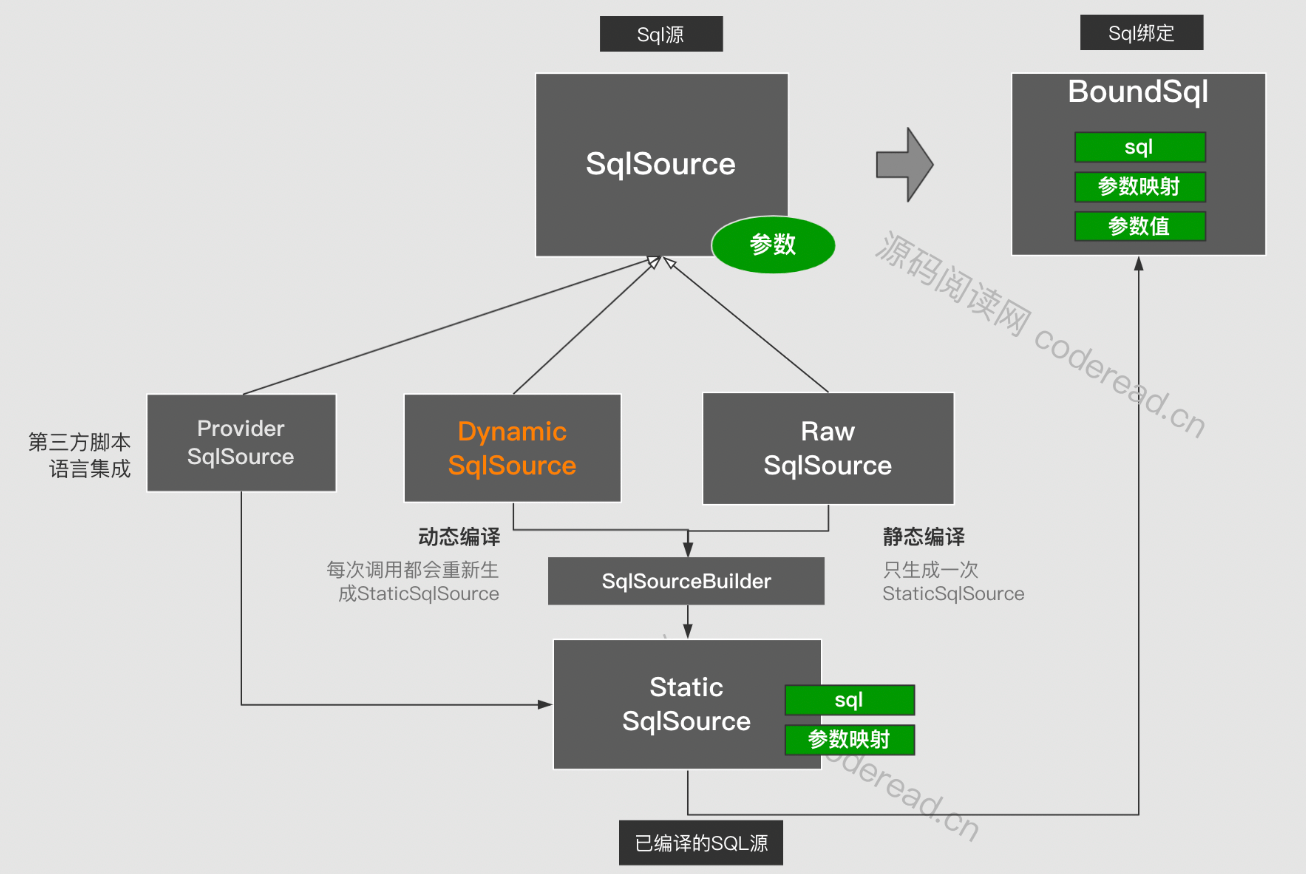
- ProviderSqlSource :第三方法SQL源,每次获取SQL都会基于参数动态创建静态数据源,然后在创建BoundSql
- DynamicSqlSource:动态SQL源包含了SQL脚本,每次获取SQL都会基于参数又及脚本,动态创建创建BoundSql
- RawSqlSource:不包含任何动态元素,原生文本的SQL。但这个SQL是不能直接执行的,需要转换成BoundSql
- StaticSqlSource:包含可执行的SQL,以及参数映射,可直接生成BoundSql。前面三个数据源都要先创建StaticSqlSource然后才创建BoundSql。
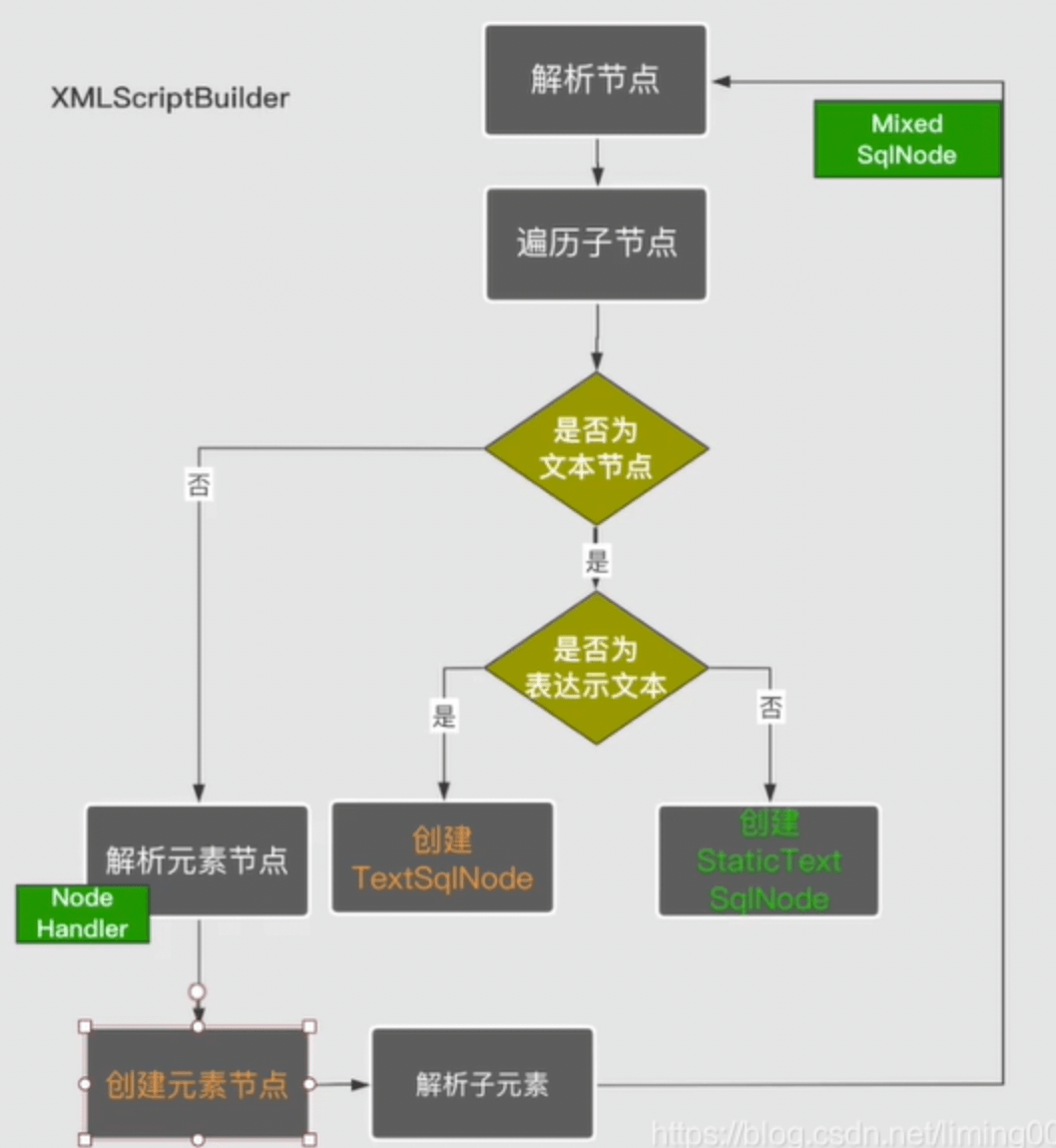
SqlSource 是基于XML解析而来,解析的底层是使用Dom4j 把XML解析成一个个子节点,在通过 XMLScriptBuilder 遍历这些子节点最后生成对应的Sql源。其解析流程如下图:

从图中可以看出这是一种递归式的访问 所有节点,如果是文本节点就会直接创建TextNode 或StaticSqlNode。否则就会创建动态脚本节点如IfSqlNode等。这里每种动态节点都会对应的处理器(NodeHandler)来创建。创建好之后又会继续访问子节点,让递归继续下去。当然子节点所创建的SqNode 也会作为当前所创建的元素的子节点而存在。
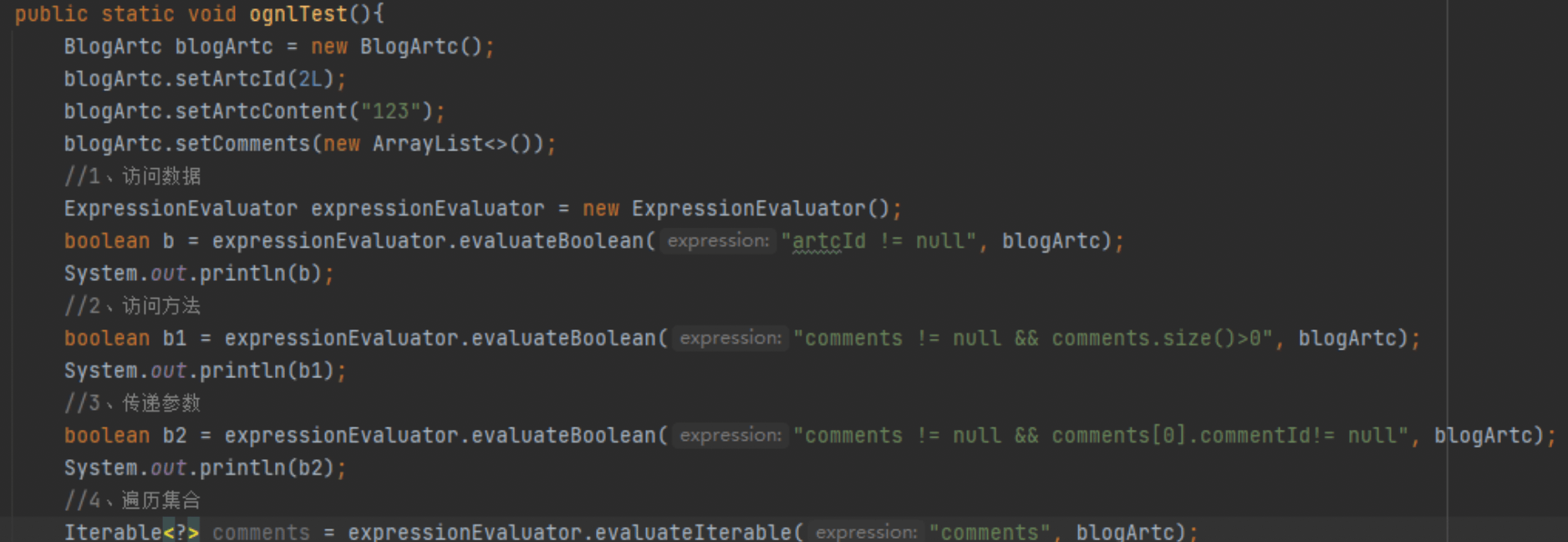
OGNL表达式简单使用:
IF和Where节点的执行:
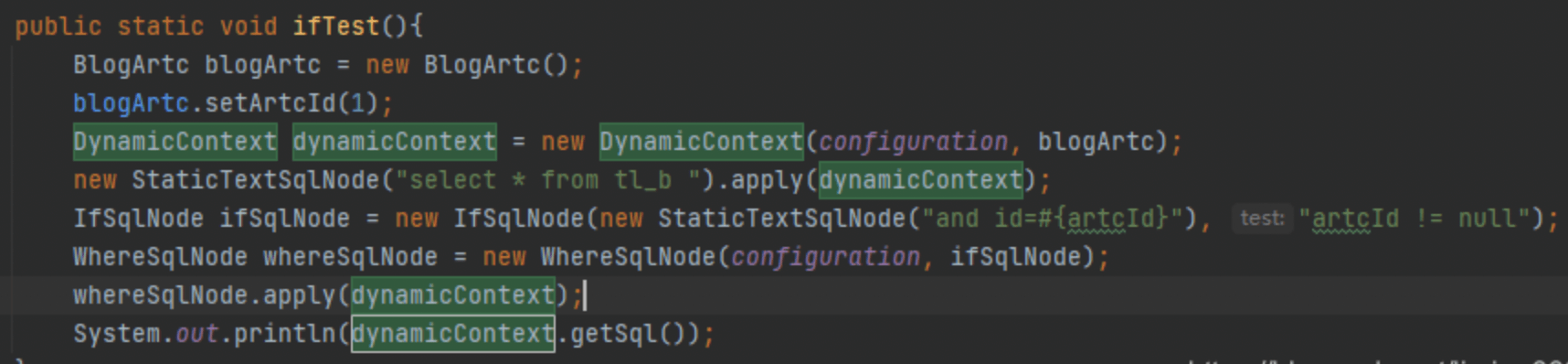
其实就是数据简单的字符串拼装 ,通过where看到,是继承 TrimSqlNode:
/**
* `<where />` 标签的 SqlNode 实现类
*
* @author Clinton Begin
*/
public class WhereSqlNode extends TrimSqlNode {
private static List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
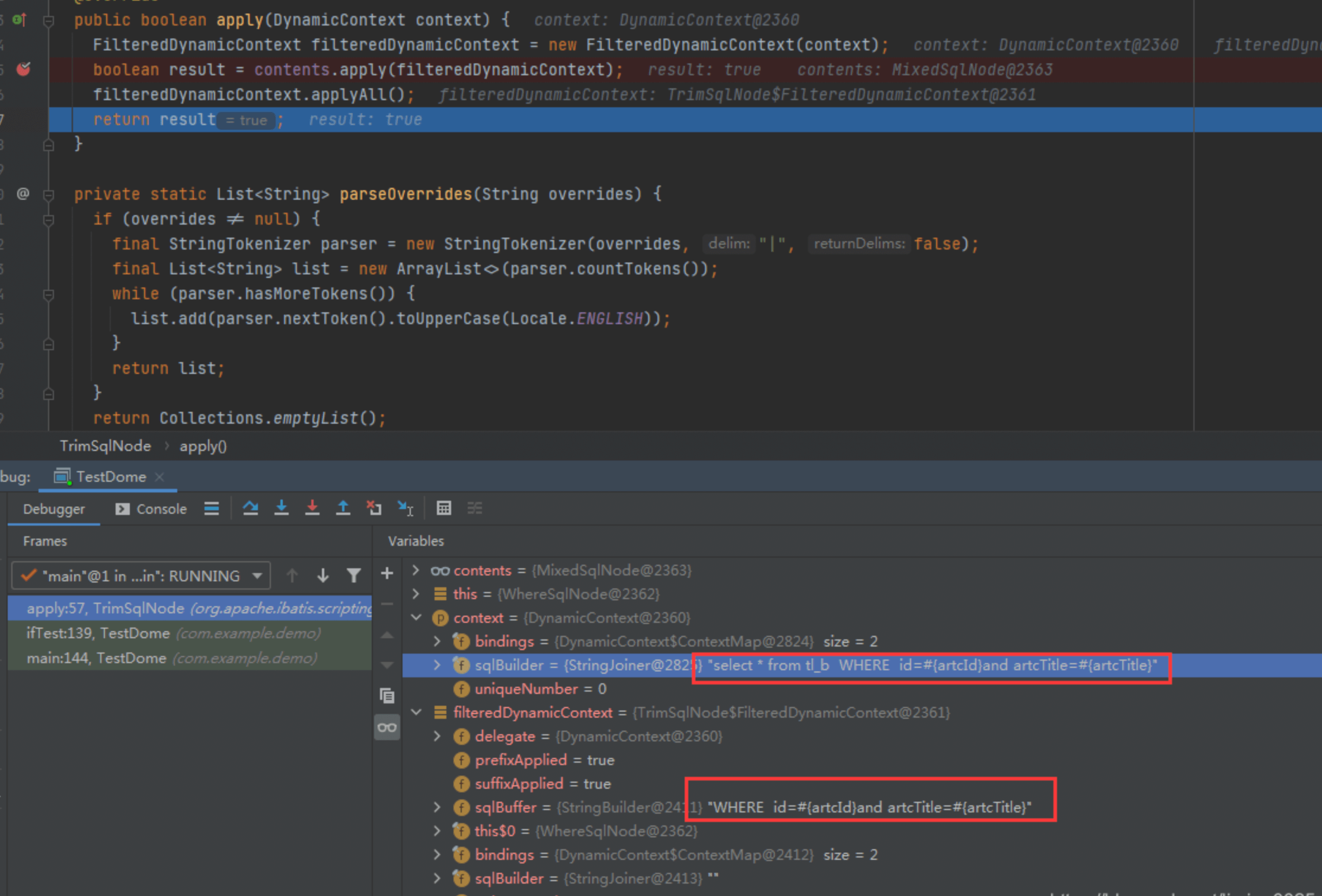
TrimSqlNode的源码,就是遍历where里面的相关节点,然后截取或者增加相关内容,然后放入一个自有的上下文中,然后进行相关拼装,最后放入整体上下文。
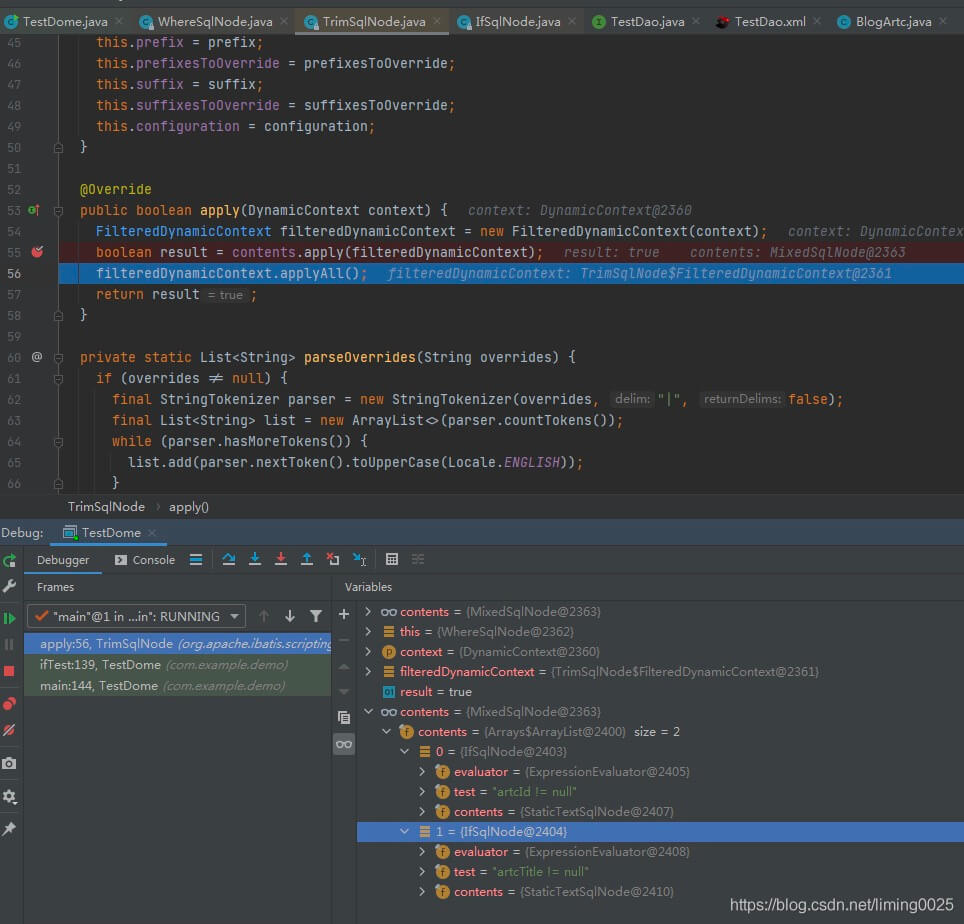
可以看到buffer中是修剪完毕的sql,同时applyAll之后,就是把buffer中的数据,追加到context中:
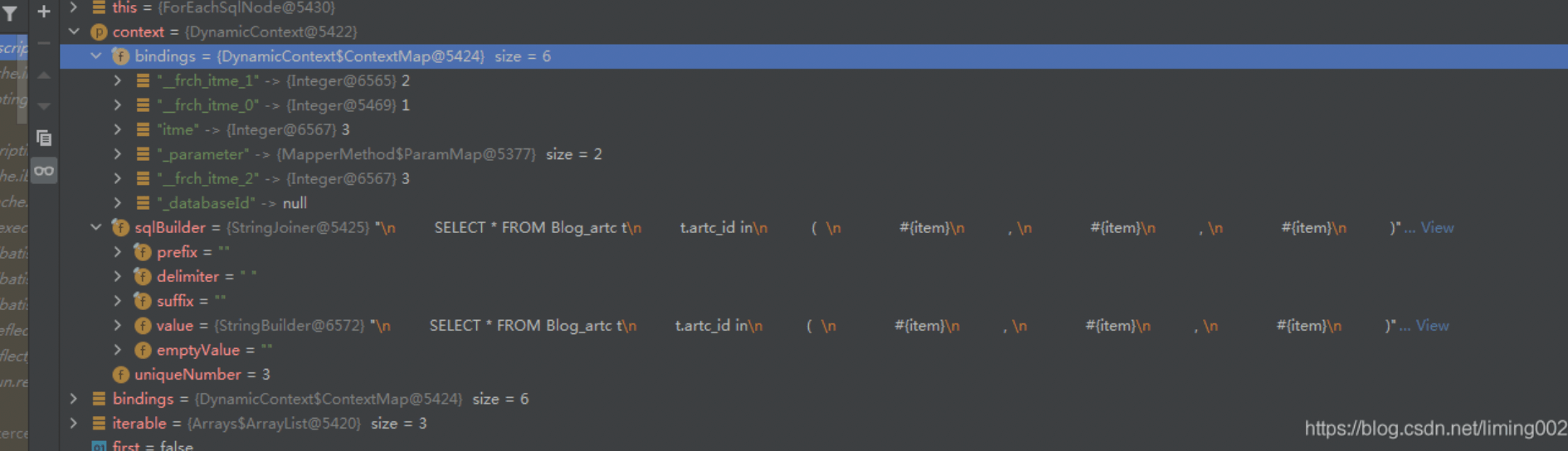
foreach操作:先根据传入是list还是map,因为循环的时候,需要根据集合内部的数据拼装成参数
#{item_1},#{item_2},如果是map这拼接成#{item_key1},#

XML的解析过程(xml->SqlSource):